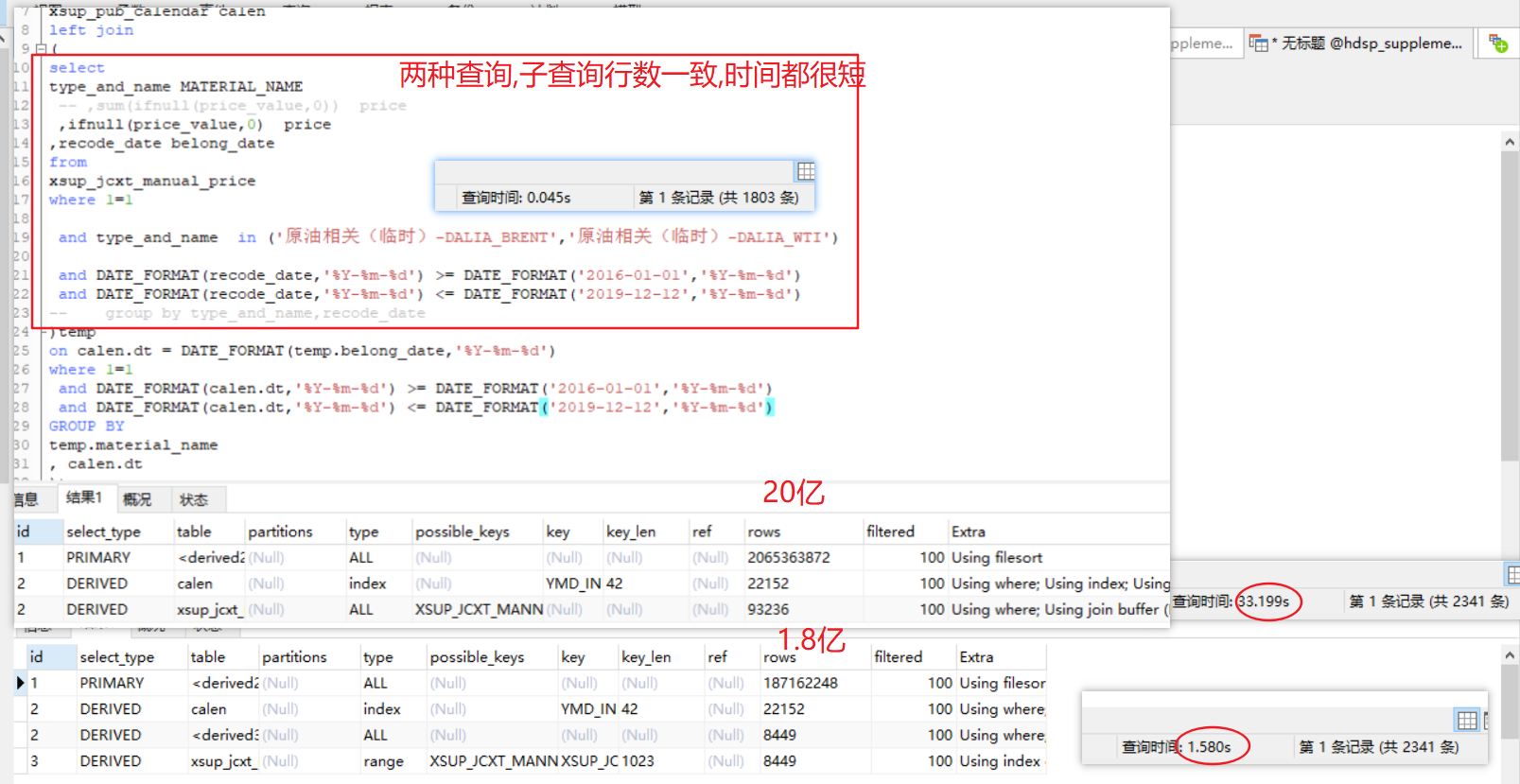
如图,我子查询里面, 把注释掉的两行,放开
即在子查询里面加一个group by
,会让计算记录数减少18亿,查询时间减少30多秒
两种写法,子查询的记录数是一样的,都是1803条
求问,这个是为什么?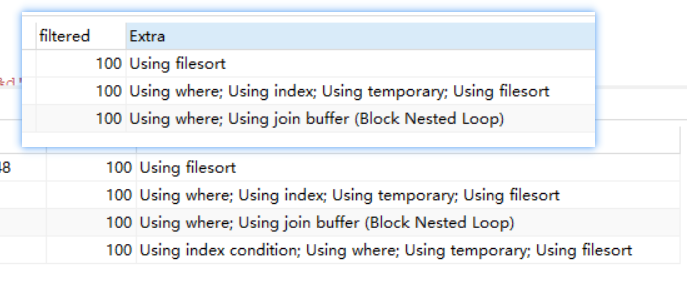
上图是完整的explain说明

如图,我子查询里面, 把注释掉的两行,放开
即在子查询里面加一个group by
,会让计算记录数减少18亿,查询时间减少30多秒
两种写法,子查询的记录数是一样的,都是1803条
求问,这个是为什么?
上图是完整的explain说明
 分享
分享 set@@sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_pISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
去掉ONLY_FULL_GROUP_BY即可正常执行sql.
分享



