
keras中fit方法解释y参数可输入字典映射,请问输入格式应该是怎么样的呢?
keras.model.fit()方法源码解释如下:
y: Numpy array of target (label) data
(if the model has a single output),
or list of Numpy arrays (if the model has multiple outputs).
If output layers in the model are named, you can also pass a
dictionary mapping output names to Numpy arrays.
目前model.fit()参数设置如下:
self.model.fit(dataset.train_images,
dataset.train_labels,
batch_size=batch_size,
epochs=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels),
callbacks=callbacks,
shuffle=True)
其中dataset.train_images 的shape为: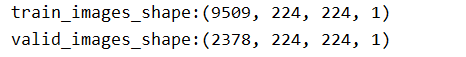
传入的标签字典dataset.train_labels的形式为: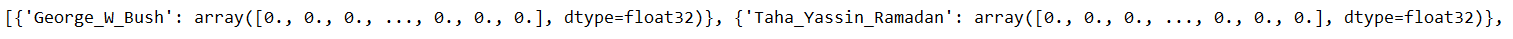
报错图片:
请问应该如何设置fit()方法中的y参数才能让模型训练出来预测时输出对应的映射名字。




