关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
yangispondering
2020-03-12 21:09
采纳率: 0%
浏览 4133
首页
人工智能
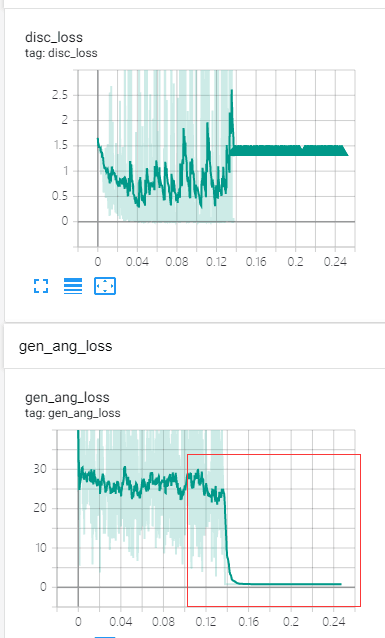
GAN网络训练过程中,生成器的一项loss会突然断崖式下降到0,然后判别器的loss变为NAN,请问是什么原因?
神经网络
tensorflow
人工智能
深度学习
loss图如下:
网上的大多数方法都试了,不起效果
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
4
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
weixin_49672296
2020-11-22 15:03
关注
这个图是怎么显示的呀~~求教
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(3条)
向“C知道”追问
报告相同问题?
提交
关注问题
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告

 分享
分享

