
import requests
from lxml import etree
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
r = requests.get('https://book.douban.com/subject/34857216/comments/hot?p={1-3}',headers=headers)
t=r.text
s=etree.HTML(t)
x=(s.xpath('//*[@id="comments"]/ul[1]/li/div[2]/p/span/text()')) #浏览器复制
import pandas as pd
import numpy as np
df=pd.DataFrame(x)
df.to_csv('duanping6.csv',encoding="utf_8_sig")
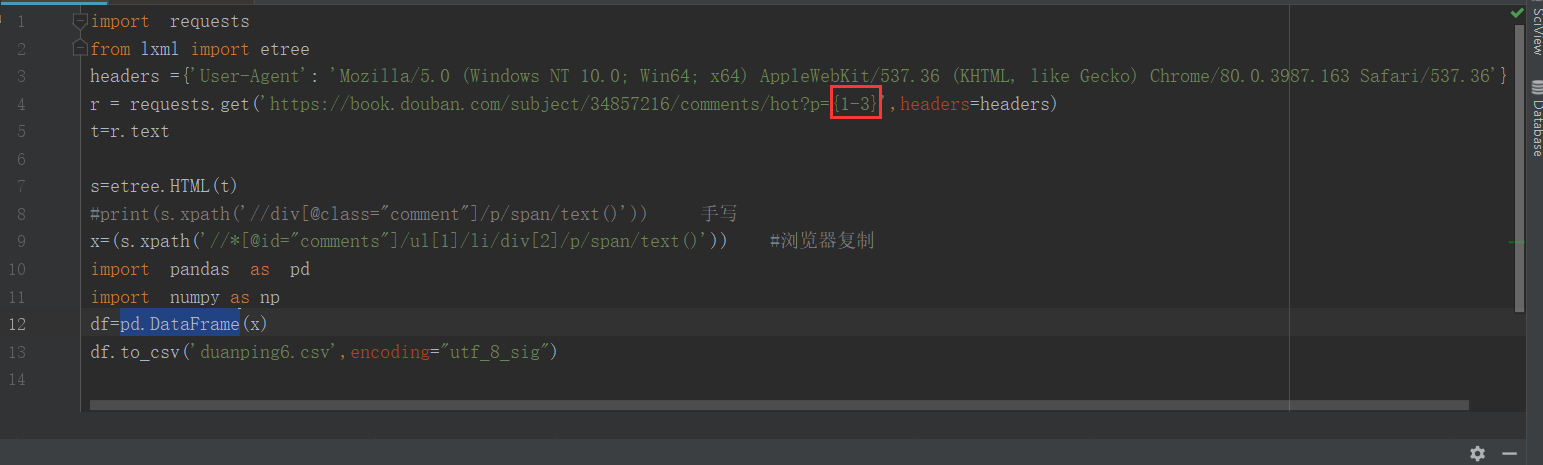
请教一下各位大神,请问这个什么原因导致只能爬取保存第一页的数据,是因为url写的有问题吗?






