
import pickle
import docx
import re
import os
from bistmCRF import BiLSTM_CRF
import torch.optim as optim
import torch
import time
EPOCHES =3
EMBEDDING_DIM = 300
HIDDEN_DIM = 500
BATCH_SIZE = 64
learning_rate = 0.001
labels_list = {"SUB": 0, "TEM": 1, "LOC": 2, "RAI": 3, "ACT": 4, "ATT": 5}
delet = ["-1", "-2", "-3", "-4", "-P", "-C", "-W", "-S", "-R", "V", '-L']
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
def extract(path):
fulllist = []
contents = []
f = docx.Document(path)
parg = f.paragraphs
for p in parg:
fulllist.append(p.text)
fulllist = fulllist[5:len(fulllist)-4]
for list in fulllist:
contents += re.findall(r'[\[](.*?)[\]]', list)
lables = []
data = {}
for content in contents:
content = content.replace(" ", "")
for lable in labels_list.keys():
if lable in content:
lables.append(lable)
content = content.replace(lable, "")
if content[:2] in delet:
content = content[2:]
data[content] = lable
break
return data
def apart_label_data(content):
content_label, content_data = [], []
for con in content:
content_label += con.values()
content_data += con.keys()
return content_data, content_label
def to_ix_processing(pairs):
word_to_ix = {}
tag_to_ix= {"<START>": 0, "<STOP>": 1, "<UNK>": 2}
for pair in pairs:
for word, tags in pair.items():
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
if tags not in tag_to_ix:
tag_to_ix[tags] = len(tag_to_ix)
return word_to_ix, tag_to_ix
def prepare_sequence(datas, word_to_ix):
idx = []
for w in datas:
if w not in word_to_ix.keys():
w = 'UNK'
idx.append(word_to_ix[w])
return torch.tensor(idx, dtype=torch.long)
def trains(model, optimizer, train_data, train_label, to_ix_w, to_ix_l, epoch):
model.train()
model = model.cuda()
total_loss = 0
start_time = time.time()
model.zero_grad()
# prepare_sequence是将数据转换成对应的idx
sentence_in = prepare_sequence(train_data, to_ix_w).cuda()
tragets = prepare_sequence(train_label, to_ix_l).cuda()
loss = model.neg_log_likelihood(sentence_in, tragets).cuda()
total_loss += loss.item() / len(sentence_in)
log_interval = 20
cur_loss = total_loss / log_interval
elapse = time.time() - start_time
total_loss = 0
start_time = time.time()
loss.backward()
optimizer.step()
def evaluate(eval_model, test_data, test_label, to_ix_w, to_ix_l):
eval_model.eval()
total_loss = 0
sentence_in = prepare_sequence(test_data, to_ix_w).cuda()
tragets = prepare_sequence(test_label, to_ix_l).cuda()
with torch.no_grad():
loss_test = eval_model.neg_log_likelihood(sentence_in, tragets).cuda()
total_loss += float(loss_test) / len(sentence_in)
return total_loss
def main():
data_all = []
path = '标注案情750'
files = os.listdir(path)
pairs = []
#将原本结构化数据抽取出来
for file in files:
file_dir = os.path.join(path, file)
data = extract(file_dir)
data_all.append(data)
to_ix_w, to_ix_l = to_ix_processing(data_all)
#定义模型和优化器
model = BiLSTM_CRF(len(to_ix_w), to_ix_l, EMBEDDING_DIM, HIDDEN_DIM)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model = model.cuda()
#将数据划分为8:2的训练集和测试集
start = int(len(data_all) * 0.8)
train = data_all[:start]
test = data_all[start:]
#将训练集和测试集数据和标签分开
train_data, train_label = apart_label_data(train)
test_data, test_label = apart_label_data(test)
for epoch in range(EPOCHES):
trains(model, optimizer, train_data, train_label, to_ix_w, to_ix_l, epoch)
val_loss = evaluate(model, test_data, test_label, to_ix_w, to_ix_l)
print('|epoch{:3d}|' "loss{:5.5f}".format(epoch, val_loss))
if __name__== '__main__':
main()
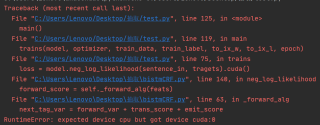
实在找不到问题,求大佬们帮忙!!!!






