根据吴恩达的讲解,下界函数是 根据《统计学习方法-李航》,得到的下界函数是
两者log后的函数不同,吴恩达的公式化简后是p(x;)而李航是p(x,z;) 不知道哪个是准确的
收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
报告相同问题?
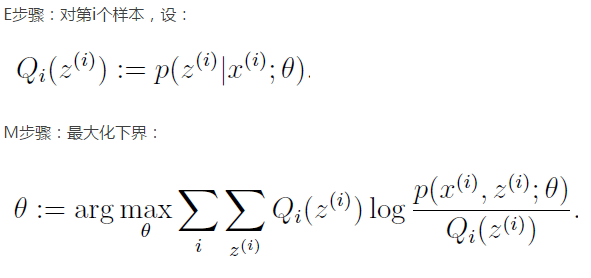
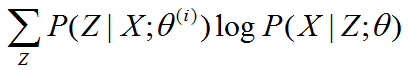

 分享
分享




