import numpy
import pandas
import matplotlib
#http://www.lfd.uci.edu/~gohlke/pythonlibs/#python-levenshtein
import Levenshtein
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
from mpl_toolkits.basemap import Basemap
from matplotlib.collections import PatchCollection
font = {
'family' : 'SimHei'
};
matplotlib.rc('font', **font);
fig = plt.figure()
ax = fig.add_subplot(111)
basemap = Basemap(
llcrnrlon=73.55770111084013,
llcrnrlat=18.159305572509766,
urcrnrlon=134.7739257812502,
urcrnrlat=53.56085968017586
)
chinaAdm1 = basemap.readshapefile(
'D:\PDA\6.6\china\CHN_adm1',
'china'
)
data = pandas.read_csv(
'D:\PDA\6.6\province.csv',
sep="\t"
)
data['总人口'] = data.总人口.str.replace(",", "").astype(int)
data['scala'] = (
data.总人口-data.总人口.min()
)/(
data.总人口.max()-data.总人口.min()
)
#数据处理:如何把JSON格式的数据,转换称为Data Frame的格式化数据
mapData = pandas.DataFrame(basemap.china_info)
#字段匹配第二大招:模糊匹配,从列表中,匹配出最大匹配度的项作为匹配项
def fuzzyMerge(df1, df2, left_on, right_on):
suitSource=[]
suitTarget=[]
suitRatio=[]
df2 = df2.groupby(
right_on
)[right_on].agg({
right_on: numpy.size
})
df2[right_on] = df2.index
for df1Index, df1Row in df1.iterrows():
for df2Index, df2Row in df2.iterrows():
if Levenshtein.ratio(df2Row[right_on], df1Row[left_on])!=0:
suitSource.append(df1Row[left_on])
suitTarget.append(df2Row[right_on])
suitRatio.append(Levenshtein.ratio(df2Row[right_on], df1Row[left_on]))
suitDataFrame = pandas.DataFrame({
right_on: suitTarget,
'suitRatio':suitRatio,
'suitSource':suitSource
})
suitDataFrame = suitDataFrame.drop_duplicates();
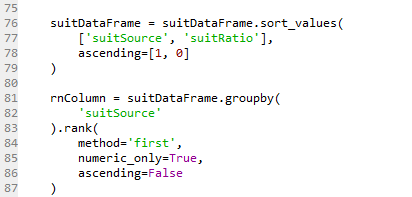
suitDataFrame = suitDataFrame.sort_values(
['suitSource', 'suitRatio'],
ascending=[1, 0]
)
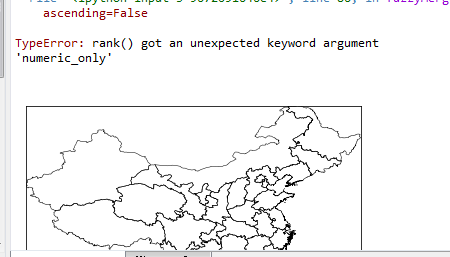
rnColumn = suitDataFrame.groupby(
'suitSource'
).rank(
method='first',
numeric_only=True, # TypeError 报错
ascending=False
)
suitDataFrame['rn'] = rnColumn;
suitDataFrame = suitDataFrame[suitDataFrame.rn==1]
data = df1.merge(
suitDataFrame,
left_on=left_on,
right_on="suitSource"
)
del data['rn'];
del data['suitRatio'];
del data['suitSource'];
return data;
fData = fuzzyMerge(data, mapData, '地区', 'NL_NAME_1')
def plotProvince(row):
mainColor = (42/256, 87/256, 141/256, row['scala']);
patches = []
for info, shape in zip(basemap.china_info, basemap.china):
if info['NL_NAME_1']==row['NL_NAME_1']:
patches.append(Polygon(numpy.array(shape), True))
ax.add_collection(
PatchCollection(
patches, facecolor=mainColor,
edgecolor=mainColor, linewidths=1., zorder=2
)
)
fData.apply(lambda row: plotProvince(row), axis=1)
dataLoc = pandas.read_csv('D:\PDA\6.6\provinceLoc.csv');
def plotText(row):
plt.text(row.jd, row.wd, row.city, fontsize=14, fontweight='bold', ha='center',va='center',color='r')
dataLoc.apply(lambda row: plotText(row), axis=1)
plt.show()