我爬取下厨房的作品url(比如这个界面:http://www.xiachufang.com/cook/10585157/created/)
*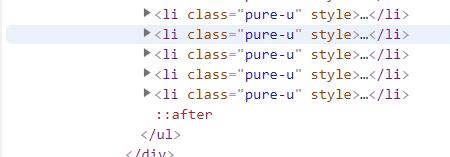
其中::after的内容需要我鼠标滚动到下面才显示。导致我python爬下来的url数量很少,只有最开始的15组。
我用的etree.html和xpath。
大家有什么方法能让我爬取到::after里的数据。

我爬取下厨房的作品url(比如这个界面:http://www.xiachufang.com/cook/10585157/created/)
*
其中::after的内容需要我鼠标滚动到下面才显示。导致我python爬下来的url数量很少,只有最开始的15组。
我用的etree.html和xpath。
大家有什么方法能让我爬取到::after里的数据。
 分享
分享





