
用深度神经网络进行训练时,将每个step计算出的梯度grad保存进一个list(见下方代码段第20行)
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape: # 构建梯度记录环境
# 插入通道维度,=>[b,32,32,1]
intermediate_out = conv_net(x, training=True)
intermediate_out = tf.reshape(intermediate_out, [-1, 512])
out = fc_net(intermediate_out, training=True)
# 真实标签 one-hot 编码,[b] => [b, 10]
y_one_hot = tf.one_hot(y, depth=10)
# 计算交叉熵损失函数,标量
loss = tf.losses.categorical_crossentropy(y_one_hot, out, from_logits=True)
loss = tf.reduce_mean(loss)
# 列表合并,合并 2 个子网络的参数
variables = conv_net.trainable_variables + fc_net.trainable_variables
# 对所有参数求梯度
grads = tape.gradient(loss, variables)
# 将grads保存进一个list中
grad_list.append(grads)
optimizer.apply_gradients(zip(grads, variables))
然后创建另一个一模一样的神经网络,并使用刚刚保存的grads-list中的每个grads依次对该神经网络进行梯度下降
# 加载刚刚保存的相同的VGG-13网络,利用刚刚生成的grad进行梯度下降
t_conv_net = models.load_model('conv_net0.h5', compile=False)
t_fc_net = models.load_model('fc_net0.h5', compile=False)
# 训练前测试一下模型准确率
t_accuracy_before = run_test(t_conv_net, t_fc_net, test_db)
print("t_accuracy before train = ", t_accuracy_before)
t_variables = t_conv_net.trainable_variables + t_fc_net.trainable_variables
for gg in grad_list:
optimizer.apply_gradients(zip(gg, t_variables))
理论上经过这一轮训练,应该得到两个完全相同的训练后的模型,因为两个模型初始化相同,使用了相同的梯度grads进行梯度下降来训练它们的参数。然而结果却并非如此,第一个模型经过这一轮训练,测试准确率从0.11左右提升至了0.4左右;而第二个模型的测试准确率却几乎没有变化。
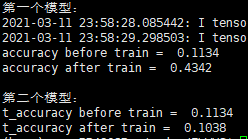
请各位大佬指导一下,为什么使用相同的梯度进行梯度下降,却会得到不同的结果?万分感激!
完整代码如下所示:
import os
import numpy as np
import math
import tensorflow as tf # 导入 TF 库
from tensorflow.keras import layers, Sequential, losses, optimizers, datasets, models
import matplotlib.pyplot as plt
# 设置 GPU 显存使用方式为:为增长式占用-----------------------
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try: # 设置 GPU 为增长式占用
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
# 打印异常
print(e)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.random.set_seed(2345)
def vgg13():
conv_layers = [
# 先创建包含多网络层的列表
# Conv-Conv-Pooling 单元 1
# 64 个 3x3 卷积核, 输入输出同大小
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
# 高宽减半
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# Conv-Conv-Pooling 单元 2,输出通道提升至 128,高宽大小减半
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# Conv-Conv-Pooling 单元 3,输出通道提升至 256,高宽大小减半
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# Conv-Conv-Pooling 单元 4,输出通道提升至 512,高宽大小减半
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# Conv-Conv-Pooling 单元 5,输出通道提升至 512,高宽大小减半
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
# 利用前面创建的层列表构建网络容器
conv_net = Sequential(conv_layers)
# 创建 3 层全连接层子网络
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(10, activation=None),
])
# build2 个子网络,并打印网络参数信息
conv_net.build(input_shape=[None, 32, 32, 3])
fc_net.build(input_shape=[None, 512])
return conv_net, fc_net
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32) # 类型转换
return x, y
def generating_data_set(input_x, input_y, batch):
# 构建训练集对象,随机打乱,预处理,批量化
db = tf.data.Dataset.from_tensor_slices((input_x, input_y))
db = db.shuffle(1000).map(preprocess).batch(batch) # 构建测试集对象,预处理,批量化
return db
def run_test(conv_net, fc_net, test_db):
# 记录预测正确的数量,总样本数量
correct_num, total_num = 0, 0
for x, y in test_db: # 遍历所有训练集样本
# 插入通道维度,=>[b,28,28,1]
intermediate_out = conv_net(x, training=False)
intermediate_out = tf.reshape(intermediate_out, [-1, 512])
out = fc_net(intermediate_out, training=False)
# 先经过 softmax,再 argmax
prob = tf.nn.softmax(out, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
correct_num += int(correct)
# 计算准确率
accuracy = correct_num / total_num
return accuracy
(x, y), (x_test, y_test) = datasets.cifar10.load_data() # 数据集为cifar10
# 删除 y 的一个维度,[b,1] => [b]
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
train_db = generating_data_set(x, y, 128)
test_db = generating_data_set(x_test, y_test, 64)
grad_list = [] # 用于存储每个step产生的梯度grad
conv_net, fc_net = vgg13() # 使用的神经网络为VGG-13
optimizer = optimizers.Adam(lr=1e-4)
# 将神经网络保存
conv_net.save('conv_net0.h5')
fc_net.save('fc_net0.h5')
print("第一个模型:")
# 训练前测试一下模型准确率
accuracy_before = run_test(conv_net, fc_net, test_db)
print("accuracy before train = ", accuracy_before)
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape: # 构建梯度记录环境
# 插入通道维度,=>[b,32,32,1]
intermediate_out = conv_net(x, training=True)
intermediate_out = tf.reshape(intermediate_out, [-1, 512])
out = fc_net(intermediate_out, training=True)
# 真实标签 one-hot 编码,[b] => [b, 10]
y_one_hot = tf.one_hot(y, depth=10)
# 计算交叉熵损失函数,标量
loss = tf.losses.categorical_crossentropy(y_one_hot, out, from_logits=True)
loss = tf.reduce_mean(loss)
# 列表合并,合并 2 个子网络的参数
variables = conv_net.trainable_variables + fc_net.trainable_variables
# 对所有参数求梯度
grads = tape.gradient(loss, variables)
# 将grads保存进一个list中
grad_list.append(grads)
optimizer.apply_gradients(zip(grads, variables))
# 训练后测试一下模型准确率
accuracy_after = run_test(conv_net, fc_net, test_db)
print("accuracy after train = ", accuracy_after)
del conv_net
del fc_net
# 加载刚刚保存的相同的VGG-13网络,利用刚刚生成的grad进行梯度下降
t_conv_net = models.load_model('conv_net0.h5', compile=False)
t_fc_net = models.load_model('fc_net0.h5', compile=False)
print("\n第二个模型:")
# 训练前测试一下模型准确率
t_accuracy_before = run_test(t_conv_net, t_fc_net, test_db)
print("t_accuracy before train = ", t_accuracy_before)
t_variables = t_conv_net.trainable_variables + t_fc_net.trainable_variables
for gg in grad_list:
optimizer.apply_gradients(zip(gg, t_variables))
# 训练后测试一下模型准确率
t_accuracy_after = run_test(t_conv_net, t_fc_net, test_db)
print("t_accuracy after train = ", t_accuracy_after)



