

Order = pd.read_csv('Order.csv', header=None, names=['date', 'time', 'city', 'id', 'zl', 'xse', 'sl', 'zk', 'lr'])
sorted = Order.groupby(['zl','city']).agg(sum=('xse','sum')).sort_values(by='sum')
df =sorted.sort_values(['zl','city'])
print(df)
这种代码输出:
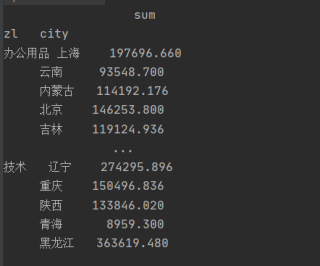
他的index索引:
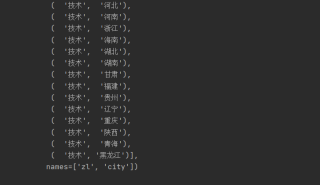
像这种index有两列,我应该怎么用pandas来提取 (zl="技术”) 后面xse的数值。





