各位大神,我把整个需求描述出来,昨天提出的已经被采纳,非常感谢,但我接触python只有两天,没有开发经验,所以还得大神帮忙看看如何解决
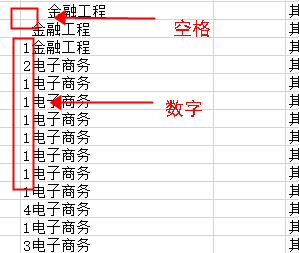
学校有张招生的数据表,列字段有100多个,由于我只需要特定的一些列字段,大概在50个左右,所以我通过usecols的方式提取出需要的字段,但是提取出来的有些字段需要处理下数据,比如【录取专业】字段,这个字段下有一部分单元格前面有空格和数字,我想通过pandas将这些字段里面这些过滤掉,然后将特定的字段保存到新的Excel中,请问该怎么写这个代码
import pandas as pd
name = (input('请输入文件名:')+'.xls')
table = pd.read_excel('work.xls',usecols=["来源省","学号","考生号","姓名","身份证","院系","录取专业"],dtype=str)
print (table)
table.to_excel(name+'转换后.xlsx',index=False)
原始数据截图: