
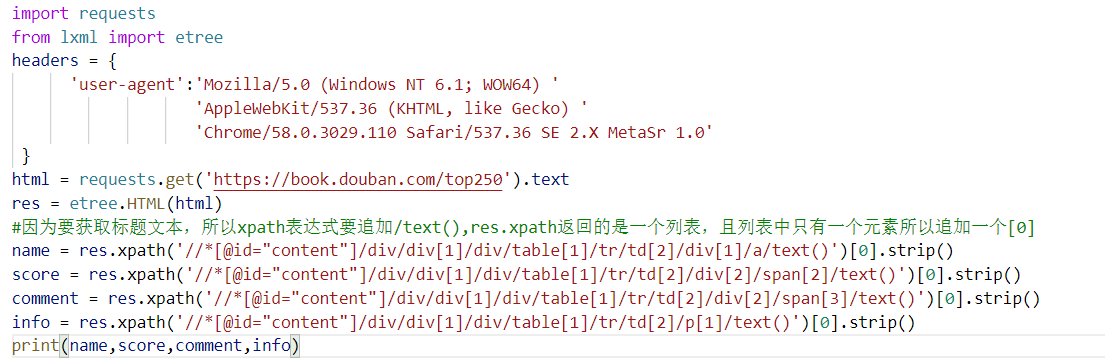
import requests
from lxml import etree
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
}
html = requests.get('https://book.douban.com/top250').text
res = etree.HTML(html)
#因为要获取标题文本,所以xpath表达式要追加/text(),res.xpath返回的是一个列表,且列表中只有一个元素所以追加一个[0]
name = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0].strip()
score = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2]/text()')[0].strip()
comment = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[3]/text()')[0].strip()
info = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/p[1]/text()')[0].strip()
print(name,score,comment,info)
为什么会出现如下的报错
AttributeError: 'NoneType' object has no attribute 'xpath'https://img-mid.csdnimg.cn/release/static/image/mid/ask/399031844726178.png)









{kind=link}