
from tensorflow.keras import backend as K
from tensorflow.keras.layers import Layer
from tensorflow.keras import activations
from tensorflow.keras import utils
from tensorflow.keras.models import Model
from tensorflow.keras.layers import *
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import TensorBoard
import mnist
import tensorflow
batch_size = 128
num_classes = 10
epochs = 20
"""
压缩函数,我们使用0.5替代hinton论文中的1,如果是1,所有的向量的范数都将被缩小。
如果是0.5,小于0.5的范数将缩小,大于0.5的将被放大
"""
def squash(x, axis=-1):
s_quared_norm = K.sum(K.square(x), axis, keepdims=True) + K.epsilon()
scale = K.sqrt(s_quared_norm) / (0.5 + s_quared_norm)
result = scale * x
return result
# 定义我们自己的softmax函数,而不是K.softmax.因为K.softmax不能指定轴
def softmax(x, axis=-1):
ex = K.exp(x - K.max(x, axis=axis, keepdims=True))
result = ex / K.sum(ex, axis=axis, keepdims=True)
return result
# 定义边缘损失,输入y_true, p_pred,返回分数,传入即可fit时候即可
def margin_loss(y_true, y_pred):
lamb, margin = 0.5, 0.1
result = K.sum(y_true * K.square(K.relu(1 - margin -y_pred))
+ lamb * (1-y_true) * K.square(K.relu(y_pred - margin)), axis=-1)
return result
class Capsule(Layer):
"""编写自己的Keras层需要重写3个方法以及初始化方法
1.build(input_shape):这是你定义权重的地方。
这个方法必须设self.built = True,可以通过调用super([Layer], self).build()完成。
2.call(x):这里是编写层的功能逻辑的地方。
你只需要关注传入call的第一个参数:输入张量,除非你希望你的层支持masking。
3.compute_output_shape(input_shape):
如果你的层更改了输入张量的形状,你应该在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状。
4.初始化方法,你的神经层需要接受的参数
"""
def __init__(self,
num_capsule,
dim_capsule,
routings=3,
share_weights=True,
activation='squash',
**kwargs):
super(Capsule, self).__init__(**kwargs) # Capsule继承**kwargs参数
self.num_capsule = num_capsule
self.dim_capsule = dim_capsule
self.routings = routings
self.share_weights = share_weights
if activation == 'squash':
self.activation = squash
else:
self.activation = activation.get(activation) # 得到激活函数
# 定义权重
def build(self, input_shape):
input_dim_capsule = input_shape[-1]
if self.share_weights:
# 自定义权重
self.kernel = self.add_weight(
name='capsule_kernel',
shape=(1, input_dim_capsule,
self.num_capsule * self.dim_capsule),
initializer='glorot_uniform',
trainable=True)
else:
input_num_capsule = input_shape[-2]
self.kernel = self.add_weight(
name='capsule_kernel',
shape=(input_num_capsule, input_dim_capsule,
self.num_capsule * self.dim_capsule),
initializer='glorot_uniform',
trainable=True)
super(Capsule, self).build(input_shape) # 必须继承Layer的build方法
# 层的功能逻辑(核心)
def call(self, inputs):
if self.share_weights:
hat_inputs = K.conv1d(inputs, self.kernel)
else:
hat_inputs = K.local_conv1d(inputs, self.kernel, [1], [1])
batch_size = K.shape(inputs)[0]
input_num_capsule = K.shape(inputs)[1]
hat_inputs = K.reshape(hat_inputs,
(batch_size, input_num_capsule,
self.num_capsule, self.dim_capsule))
hat_inputs = K.permute_dimensions(hat_inputs, (0, 2, 1, 3))
b = K.zeros_like(hat_inputs[:, :, :, 0])
for i in range(self.routings):
c = softmax(b, 1)
o = self.activation(K.batch_dot(c, hat_inputs, [2, 2]))
if K.backend() == 'theano':
o = K.sum(o, axis=1)
if i < self.routings-1:
b += K.batch_dot(o, hat_inputs, [2, 3])
if K.backend() == 'theano':
o = K.sum(o, axis=1)
return o
def compute_output_shape(self, input_shape): # 自动推断shape
return (None, self.num_capsule, self.dim_capsule)
def MODEL():
input_image = Input(shape=(32, 32, 3))
x = Conv2D(64, (3, 3), activation='relu')(input_image)
x = Conv2D(64, (3, 3), activation='relu')(x)
x = AveragePooling2D((2, 2))(x)
x = Conv2D(128, (3, 3), activation='relu')(x)
x = Conv2D(128, (3, 3), activation='relu')(x)
"""
现在我们将它转换为(batch_size, input_num_capsule, input_dim_capsule),然后连接一个胶囊神经层。模型的最后输出是10个维度为16的胶囊网络的长度
"""
x = Reshape((-1, 128))(x) # (None, 100, 128) 相当于前一层胶囊(None, input_num, input_dim)
capsule = Capsule(num_capsule=10, dim_capsule=16, routings=3, share_weights=True)(x) # capsule-(None,10, 16)
output = Lambda(lambda z: K.sqrt(K.sum(K.square(z), axis=2)))(capsule) # 最后输出变成了10个概率值
model = Model(inputs=input_image, output=output)
return model
if __name__ == '__main__':
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = tensorflow.keras.utils.to_categorical(y_train, num_classes)
y_test = tensorflow.keras.utils.to_categorical(y_test, num_classes)
# 加载模型
model = MODEL()
model.compile(loss=margin_loss, optimizer='adam', metrics=['accuracy'])
model.summary()
tfck = TensorBoard(log_dir='capsule')
# 训练
data_augmentation = True
if not data_augmentation:
print('Not using data augmentation.')
model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
callbacks=[tfck],
shuffle=True)
else:
print('Using real-time data augmentation.')
# This will do preprocessing and realtime data augmentation:
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by dataset std
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=0, # randomly rotate images in 0 to 180 degrees
width_shift_range=0.1, # randomly shift images horizontally
height_shift_range=0.1, # randomly shift images vertically
horizontal_flip=True, # randomly flip images
vertical_flip=False) # randomly flip images
# Compute quantities required for feature-wise normalization
# (std, mean, and principal components if ZCA whitening is applied).
datagen.fit(x_train)
# Fit the model on the batches generated by datagen.flow().
model.fit_generator(
datagen.flow(x_train, y_train, batch_size=batch_size),
epochs=epochs,
validation_data=(x_test, y_test),
callbacks=[tfck],
workers=4)
以上为代码
运行后出现该问题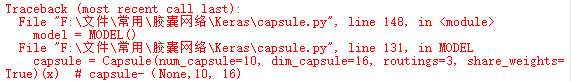

用官方的胶囊网络keras实现更改为tf下的keras实现仍出现该错误。





