
这是GPU运行情况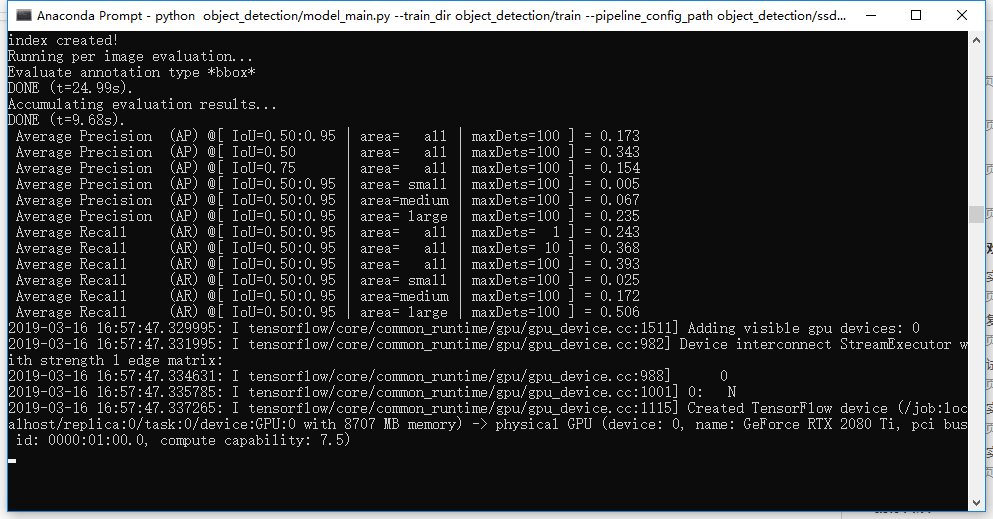
这是训练过程

用tensorflow-gpu跑SSD-Mobilenet模型GPU使用率很低这是为什么

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

5条回答 默认 最新

- 2024-10-21 05:22项目将详细介绍整个部署流程,包括如何在Jetson-TX2上安装TensorRT,如何将训练好的MobileNet-SSD模型转换为TensorRT引擎,以及如何在Jetson-TX2上进行模型的优化和测试。 项目中可能涉及的关键知识点包括:深度...
- 2025-12-26 14:30宋老师的博客的博客 本文详细记录了在Windows 10环境下基于CUDA 9.0和CUDNN 7.4编译TensorFlow 1.8.0 C++ GPU版本库的过程,涵盖环境配置、依赖安装、CMake构建参数设置及常见编译问题解决方案,并提供测试用例验证库的正确性。
- 2025-12-26 14:39媛源啊的博客 本文详细记录了在Windows 10环境下基于CUDA 9.0和CUDNN 7.4编译TensorFlow 1.8.0 GPU版C++库的过程,涵盖环境配置、依赖安装、CMake构建及常见问题解决方法。通过VS2015生成解决方案,最终成功运行矩阵乘法测试用例...
- 2025-12-21 18:02DeepSeaAI@Haibao的博客 本指南详细介绍了在Windows 11上搭建完整深度...优先使用PyTorch进行深度学习开发考虑使用WSL2获得更好的TensorFlow支持定期检查NVIDIA官网获取最新驱动和CUDA版本关注PyTorch和TensorFlow官方文档的版本兼容性说明。
- 2025-11-03 00:32QuietPulse的博客 本文通过实测数据对比了TensorFlow-GPU 2.4.1在GTX 1650 Ti显卡与CPU上的训练性能,展示了GPU加速在深度学习中的显著优势。测试结果显示,在MNIST、CIFAR-10等任务中,GPU加速比最高达14倍。文章还详细介绍了环境...
- 2020-11-30 10:38weixin_39849387的博客 我们很高兴在模型优化工具包中添加训练后的半精度浮点量化(float16 quantization),此工具套件包含混合量化(hybrid quantization)、训练后整形量化 (full integer quantization)和剪枝(pruning)。点此查看发展蓝图中...
- 2026-01-09 09:05坑货两只的博客 本文介绍了如何在星图GPU平台上自动化部署TensorFlow-v2.15镜像,以优化深度学习模型的GPU算力。通过该平台,用户可以快速搭建高性能训练环境,并应用混合精度训练、XLA编译等技巧,显著提升如图像分类等任务的模型...
- 2025-09-14 02:02tea88的博客 内容涵盖从OpenCL开发环境搭建、基础向量计算示例,到集成TensorFlow Lite GPU Delegate以加速AI模型推理的全过程。通过具体代码和性能对比,展示了GPU加速能为轻量级模型带来1.5至3倍的推理速度提升,是优化边缘AI...
- 2025-12-30 03:58周不宅的博客 通过nvidia-smi与PyTorch-CUDA镜像实现GPU资源的精准监控和性能调优,深入解析显存占用、利用率低、CUDA OOM等问题的根本原因,并提供数据加载瓶颈识别、混合精度训练、容器化环境一致性等实战解决方案,提升深度...
- 2019-12-31 16:33ourkix的博客 参考自: https://www.cnblogs.com/leviatan/p/10740105.html ... 关于如何安装tensorflow-gpu参考我这篇博客 https://blog.csdn.net/ourkix/article/deta...
- 没有解决我的问题, 去提问

