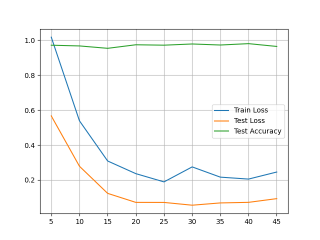
from torch import nn
from torchvision import models,datasets,transforms
import torch
import os
from torch.autograd import Variable
from torch.optim.lr_scheduler import *
data_dir = 'data'
data_transform = {
'train':transforms.Compose([transforms.Resize((150, 150)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406], [0.229,0.224,0.225]),
transforms.RandomHorizontalFlip(p=0.5),#水平翻转
transforms.RandomRotation(50), # 随机旋转
transforms.RandomResizedCrop(150)
]),
'valid':transforms.Compose([transforms.Resize((150, 150)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406], [0.229,0.224,0.225])
])
}
image_datasets = {x:datasets.ImageFolder(root=os.path.join(data_dir, x), transform=data_transform[x])
for x in ['train','valid']
}
dataloader = {x:torch.utils.data.DataLoader(dataset=image_datasets[x], batch_size=30, shuffle=True, num_workers=4)
for x in ['train','valid']
}
x_example, y_example = next(iter(dataloader['train']))
example_classes = image_datasets['train'].classes
index_classes = image_datasets['train'].class_to_idx
model = models.vgg16(pretrained=False)
# 遍历模型中的所有模块
for m in model.modules():
# 如果当前模块是卷积层或者线性层
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.constant_(m.bias, 0)
model.classifier = torch.nn.Sequential(
torch.nn.Linear(25088,512),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(512,512),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(512,2)
)
use_gpu = torch.cuda.is_available()
if use_gpu :
model = model.cuda()
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.classifier.parameters(), lr=1e-5)
epochs = 99999
global_step = 0
best_acc = 0
best_epoch = 0
with open("loss2.txt", "w") as f:
for epoch in range(epochs):
print('----' * 10)
print('Epoch {}/{}'.format(epoch + 1, epochs))
for phase in ['train', 'valid']:
if phase == 'train':
print('Training...')
model.train(True)
else:
print('Validing...')
model.train(False)
running_loss = 0.0
running_corrects = 0
for batch, data in enumerate(dataloader[phase]):
#x为数据,y为标签
x, y = data
x, y = Variable(x.cuda()), Variable(y.cuda())
#得到30个输出预测
y_pred = model(x)
#pred为预测结果
_, pred = torch.max(y_pred.data, 1)
loss = loss_f(y_pred, y)
for per in y_pred.data:
print(per)
running_loss += loss.data
if phase == 'train':
global_step += 1
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_corrects += torch.sum(pred == y.data)
epoch_loss = running_loss * 30 / len(image_datasets[phase])
epoch_acc = 100 * running_corrects / len(image_datasets[phase])
print('{} Loss:{} ACC:{}'.format(phase, epoch_loss, epoch_acc))
if(phase == 'train'):
f.writelines([str(epoch), ',', str(epoch_loss.item()),',',str(epoch_acc.item()), ','])
if(phase == 'valid'):
f.writelines([str(epoch_acc.item()),',',str(epoch_loss.item()), ';'])
f.flush()
if epoch_acc.item() > best_acc:
torch.save(model, 'best3.pth')
best_acc = epoch_acc.item()
best_epoch = epoch
print('最好的正确率是epoch:', best_epoch+1, ' 正确率为:', best_acc)
print('最好的模型在epoch:', best_epoch)
torch.save(model, 'vggmodel2.pth')
数据集在这里
链接:
百度网盘 请输入提取码
百度网盘为您提供文件的网络备份、同步和分享服务。空间大、速度快、安全稳固,支持教育网加速,支持手机端。注册使用百度网盘即可享受免费存储空间

提取码:gbuh