df1和df2合并,想要df1中的用户创建时间合并在df2相对应的用户ID后面,用了df2.join(df1),合并后的df3的行数应该和df2的行数一样。但是df3行数比df2行数多很多。
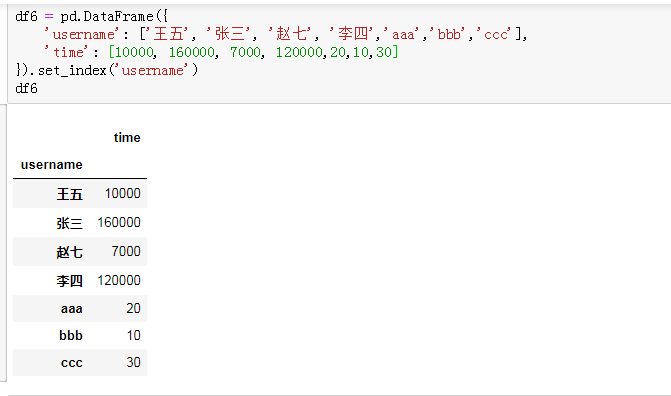
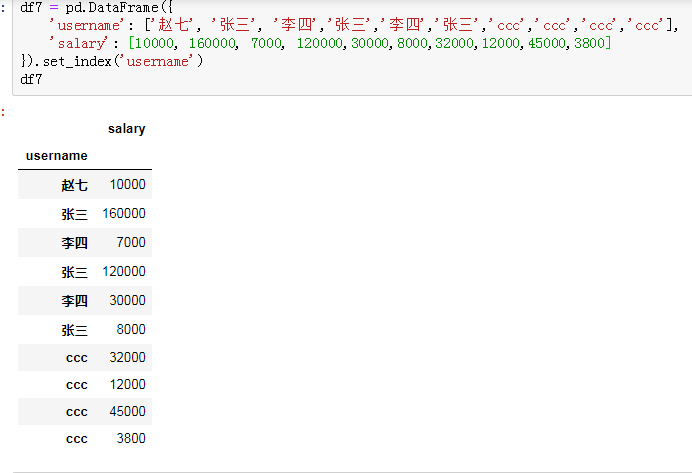
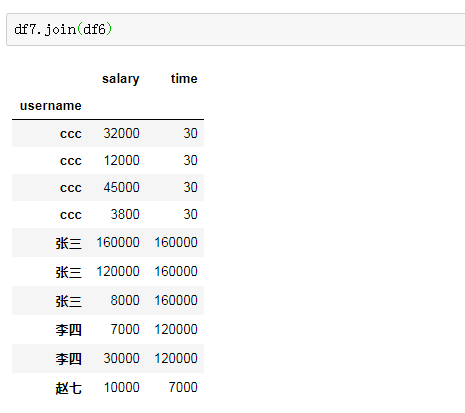
为了验证join()方法是否有效,另外新建了两个数据量小的df6和df7,结果合并后的df8是正确的想要的结果。
所以很费解为什么df1和df2用join合并就得不到正确结果。求大神指导。
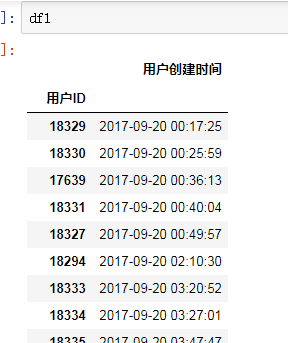
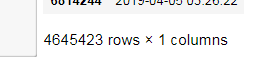
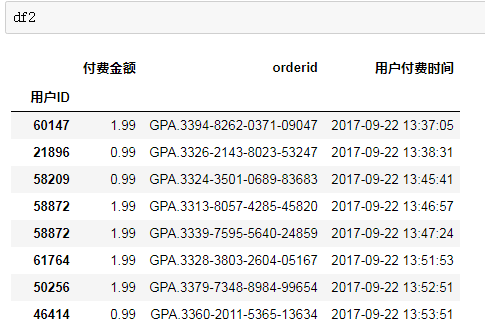
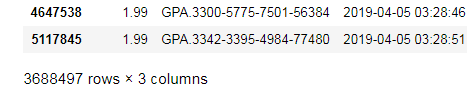
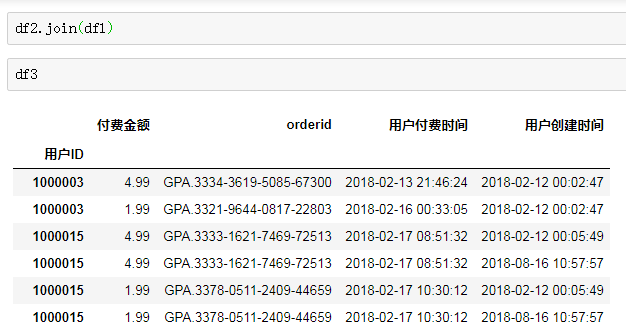


df1和df2合并,想要df1中的用户创建时间合并在df2相对应的用户ID后面,用了df2.join(df1),合并后的df3的行数应该和df2的行数一样。但是df3行数比df2行数多很多。
为了验证join()方法是否有效,另外新建了两个数据量小的df6和df7,结果合并后的df8是正确的想要的结果。
所以很费解为什么df1和df2用join合并就得不到正确结果。求大神指导。
 分享
分享
问题关键在于df1的column‘用户ID’有重复,这样使df2里一个用户ID对应df1多个相同的用户ID。这一点从df3里用户ID为1000015的多个行里有两个不同的用户账号创建时间可以得到验证。
从你给的小数据的例子来说,如果df6的username列有两个‘张三’,df7.join(df6)的结果就会多比原来多出三行,因为df7的username列有三个‘张三’。
解决方案只有查一查df1数据源有没有问题,比如造成一个用户ID会有多个创建时间的原因以及是否合理,如果df1本身合理那么和df2合并后得到的df3是否有意义?所以这取决于这个数据处理的目的是什么。
分享


