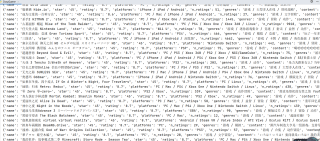
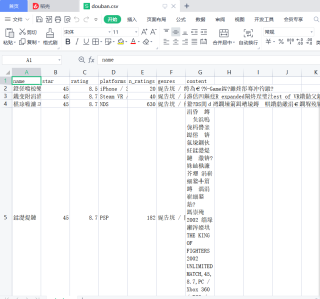
问题遇到的现象和发生背景
原地址:https://mp.weixin.qq.com/s/54dcJO2KR9aMTQJh5OlSzg
爬取数据控制台没有出问题 可是爬取到文件就出问题
问题相关代码,请勿粘贴截图
import requests
import requests
import csv
import time
import json
import requests
from lxml import etree
from pymongo import MongoClient
from bs4 import BeautifulSoup
import pandas as pd
def getOnepage(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'Cookie': 'bid=NX8M2NI7rfg; douban-fav-remind=1; __yadk_uid=TEJSv3vlFpxrnShgBGXWW51qExiqLCiD; __gads=ID=35ed214a9a0f04f3-229b40ae8cc5003e:T=1609826897:RT=1609826897:S=ALNI_MbjrOjiMxJC6bra_BWqa1z6LwJvFA; ll="118267"; viewed="1007305"; gr_user_id=38f71f7e-49a3-4463-a3e9-dd3f77625dad; _ga=GA1.2.1355032985.1609826898; _vwo_uuid_v2=D6A8A09C6232AC6A436C3775284DBE348|dadd79d0f01552308d196454329600a7; dbcl2="247324733:YcdnDsCblB0"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.24732; ck=MMTN; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1637395735%2C%22https%3A%2F%2Fwww.gameres.com%2F%22%5D; _pk_ses.100001.8cb4=*; __utma=30149280.1355032985.1609826898.1637309781.1637395736.17; __utmc=30149280; __utmz=30149280.1637395736.17.14.utmcsr=gameres.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt=1; _pk_id.100001.8cb4=b87f2f239f7dd7c8.1609826897.15.1637395743.1637309781.; __utmb=30149280.4.10.1637395736'
}
# 发送请求,得到响应
response = requests.get(url, headers=headers)
return response.json() # 文本
# 解析一页的数据
def parseOnepage (res):
col = ['name', 'star', 'rating', 'platforms', 'n_ratings', 'genres', 'content']
n = len(res['games'])
list1=[]
for j in range(n):
item={}
item['name'] = res['games'][j]['title']
item['star'] = res['games'][j]['star']
item['rating'] = res['games'][j]['rating']
item['platforms'] = res['games'][j]['platforms']
item['n_ratings'] = res['games'][j]['n_ratings']
item['genres'] = res['games'][j]['genres']
item['content'] = res['games'][j]['review']['content']
print(item)
list1.append(item)
return list1
def savaData(item):
with open('douban.csv', 'w', newline='', encoding='utf-8')as f:
fieldnames = ['name', 'star', 'rating', 'platforms', 'n_ratings',
'genres','content']
write = csv.DictWriter(f, fieldnames=fieldnames)
write.writeheader()
write.writerows(item)
def main():
for i in range(1,100):
url="https://www.douban.com/j/ilmen/game/search?genres=&platforms=&q=&sort=rating&more="+str(i)
response = getOnepage(url)
# parseOnepage(response)
savaData(parseOnepage(response))
if __name__ == '__main__': # 程序的窗口
main()
运行结果及报错内容