
小白求助,要处理一批比较大量的csv格式文件, 想根据一个list的元素来匹配CSV文件列表的第一列名称,然后对每个匹配到名称的重复项进各个列的求和(大概有几十列)。现在遇到的问题是并不是每一个单元格都有数值,很多单元格或者整行都是空白的。导致用求和时出现错误,请教下处理csv文件时遇到空单元格怎么处理。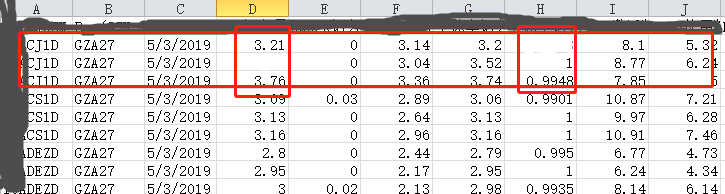
红框求和
正常情况下代码求和:
a1=[1,3,2.3,3]
a2=[5,2,3,5.5]
suma12=[c+d for (c,d) in zip(a1,a2)]
print (suma12)
#output:[6, 5, 5.3, 8.5]
遇到空白:
a1=[1,,2.3,3,,3'3]
a2=[5,2,,5.5]
suma12=[b+c for (b,c) in zip(a1,a2)]
print (suma12)
#SyntaxError: invalid syntax
类始于上面这个例子,匹配到 因为是空白单元格无法与数值相加,空白项有可能是整一行,怎么才能实现规避空白单元格求和的问题(不能用0代替),最终结果可以存在空!
白。
或许有更加方便的方法可以实现类似这样先VLOOKUP,然后透视条件各个列求和





