
用xpath定位时一直无法定位,爬虫运行后li_list一直返回为空列表。但是,在谷歌浏览器中用xpath组件
可以定位到。检查了好久,一直没有找到问题所在,请大佬们帮忙看看。
python3.6版本
def parse(self, response):
#解析内容
li_list=response .xpath('//div[@class="dlzplistcon"]/ul')
print(li_list )
#遍历列表,取出需要的数据
for oli in li_list :
# 创建一个item
item = JiuyeItem()
#获取工作名称
jobname=oli.xpath('./li/div/a/text())').extract()
print(jobname )
#获取工作链接
job_src=oli.xpath ('./li/div/a/@href').extract()
print(job_src )
#获取公司名称
company=oli.xpath ('./li/div/div/a/text()').extract()
#获取工作地点
place=oli .xpath ('./li/span[@class="r"]/text()').extract()
#获取工资
pay=oli .xpath ('./li/span[@class="m"]text()').extract()
爬取的网站是云南招聘网,下面是网站源码截图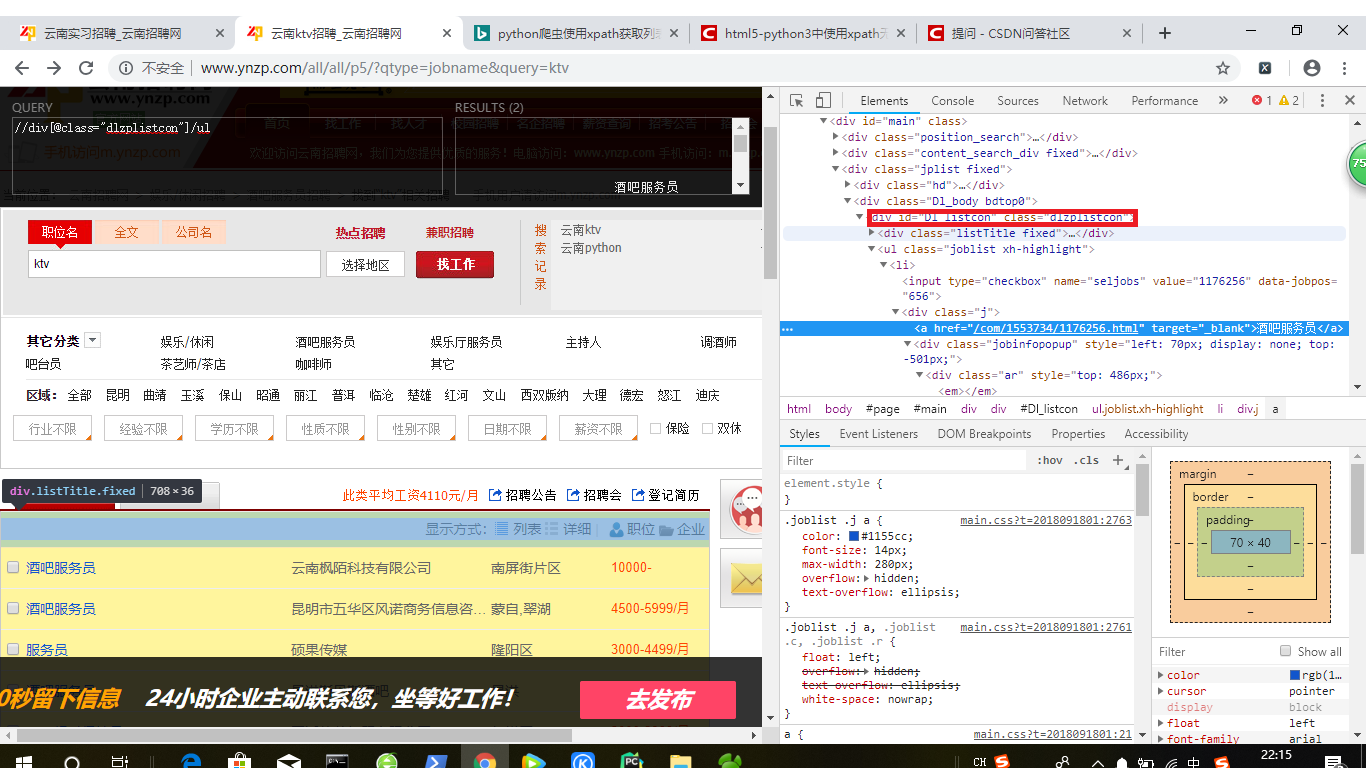
附上网站URL:http://www.ynzp.com/all/all/p5/?qtype=jobname&query=ktv





