
问题遇到的现象和发生背景
使用Scrapy抓取数据写入MySql数据库,抛出异常TypeError: __init__() missing 5 required positional arguments
问题相关代码,请勿粘贴截图
代码片段:
# 爬虫模块代码
from scrapy import Spider,Request
from urllib.parse import urlencode
import json
from ItemPipeline.items import ImageItem
class ImageSpider(Spider):
name = 'images'
start_urls = ['https://images.so.com']
def start_requests(self):
# 定义Restful API
data = {'ch':'beauty','listtype':'new'}
# 定义Restful API的参数
base_url = 'https://image.so.com/zj?'
# 通过for-in循环想服务端请求MAX_PAGE参数指定的次数
for page in range(1,self.settings.get('MAX_PAGE')+1):
# 产生每次提交的sn参数的值
data['sn'] = page * 30
# 将data编码成URL参数(主要转换某些无法放在URL中的特殊字符,如空格)
params = urlencode(data)
# 组成完整的URL
url = base_url + params
# 通过yield实现一个产生器,只有读取,才会返回当前的Request
yield Request(url,self.parse)
# 分析HTTP响应信息(Response)
def parse(self, response, **kwargs):
# 将HTTP响应信息抓好为JSON对象
result = json.loads(response.text)
# 得到list属性中的每一个元素
for image in result.get('list'):
item = ImageItem()
item['id'] = image.get('imageid')
item['url'] = image.get('qhimg_url')
item['title'] = image.get('group_title')
item['thumb'] = image.get('qhimg_thumb_url')
yield item
# 管道中间件的代码
from itemadapter import ItemAdapter
class ItempipelinePipeline:
def process_item(self, item, spider):
return item
import pymongo
import pymysql
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class MysqlPipeline():
def __init__(self, host, database, user, password, port):
self.host = host
self.database = database
self.user = user
self.password = password
self.port = port
@classmethod
def from_crawl(cls,crawler):
# 创建MysqlPipeline类的实例
return cls(
host=crawler.settings.get('MYSQL_HOST'),
database=crawler.settings.get('MYSQL_DATABASE'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
port=crawler.settings.get('MYSQL_PORT'),
)
def open_spider(self,spider):
# 连接数据库
self.db = pymysql.connect(host=self.host,user=self.user,password=self.password,database=self.database,
charset='utf8',port=self.port)
self.cursor = self.db.cursor()
def close_spider(self,spider):
# 关闭数据库
self.db.close()
def process_item(self,item,spider):
print(item['title'])
data = dict(item)
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'insert into %s (%s) values (%s)' % (item.table, keys, values)
# 将与图片相关的数据插入MySQL数据库的images表中
self.cursor.execute(sql,tuple(data.values()))
self.db.commit()
return item
# 将图片保存到本地
class ImagePipeline(ImagesPipeline):
# 返回对应本地图像文件的文件名
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
# 过滤不符合条件的图片,单个Item对象完成下载后调用该方法
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok,x in results if ok]
if not image_paths:
# 抛出异常,剔除当前下载的图片
raise DropItem('Image Downloaded Failed')
return item
# 根据当前URL创建Request对象,并返回该对象,Request对象会加到调度队列中猪呢比下载该图像
def get_media_requests(self, item, info):
yield Request(item['url'])
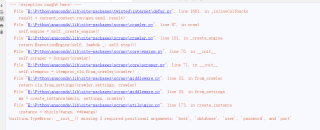
运行结果及报错内容





