
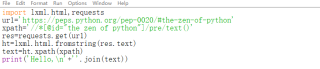
import lxml.html,requests
ur1='https://peps.python.org/pep-0020/#the-zen-of-python'
xpath='//*[@id="the zen of python"]/pre/text()'
res=requests.get(ur1)
ht=lxml.html.fromstring(res.text)
text=ht.xpath(xpath)
print('Hello,\n'+''.join(text))
就是这么打出来的
执行之后只能出个hello

难道是版本不行嘛,我用的也是python3.10啊








