模型训练过程中loss会突然上升然后下降,然后循环这种状态,这是什么原因呢?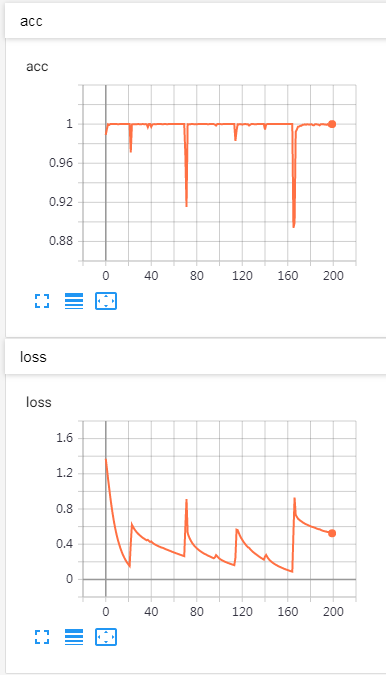

模型训练过程中loss会突然上升然后下降,然后循环这种状态,什么原因呢?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

3条回答 默认 最新
 threenewbee 2019-06-20 11:00关注
threenewbee 2019-06-20 11:00关注这很正常,因为调整权重的过程中,可能某个因素的突变会影响整个全局很多,然后再找到新的值继续降低梯度。要更多的训练看是不是过拟合
评论 打赏解决 3无用 3举报 分享
- 2025-05-12 16:30快撑死的鱼的博客 当模型在训练过程中损失函数(Loss)不再下降,或者下降非常缓慢,甚至出现上升或剧烈震荡的情况时,这表明训练过程遇到了问题。这是一个在机器学习项目调试中非常常见的现象,其背后可能的原因多种多样,可以从数据...
- 2025-05-13 19:14是麟渊的博客 在模型训练过程中,损失函数(Loss)突然出现剧烈波动(Spike)可能由多种原因引起。常见原因包括数据批次异常(如极端值或标签错误)、学习率过高或调度器故障、梯度爆炸或消失、数值不稳定性(如除以极小值或log(0...
- 2025-04-12 18:57光子AI的博客 在AI模型训练过程中,超参数调优一直是耗时且需要专业知识的环节。MCP模型上下文协议旨在解决这一痛点,通过建立模型训练过程中的上下文感知机制,实现智能化的自动参数调整。本文范围涵盖MCP协议的理论基础、实现...
- 2022-02-12 12:20ytusdc的博客 相信很多人都遇到过训练一个deep model的过程中,loss突然变成了NaN。在这里对这个问题做一个总结: 1.如果在迭代的100轮以内,出现NaN,一般情况下的原因是因为你的学习率过高,需要降低学习率。可以不断降低学习...
- 2025-01-02 16:28余弦的倒数的博客 Pytorch训练模型损失Loss为NaN或者无穷大(INF)原因及解决办法
- 2025-03-03 08:03云博士的AI课堂的博客 下面的内容将系统地介绍深度学习模型训练优化的基本方法,从端到端训练模型的构建流程,到各类性能评估指标、学习率调整、正则化方法、批量归一化、错误分析和梯度剪裁等,帮助读者在实际项目中提升模型训练效率和...
- 2023-05-28 08:06盼小辉丶的博客 在本节中,我们将了解传统机器学习与人工神经网络间的差异,并了解如何在实现前向传播之前连接网络的各个层,以计算与网络当前权重对应的损失值;实现反向传播以优化权重达到最小化损失值的目标。并将实现网络的所有...
- 2023-06-26 01:13光子AI的博客 是中一个快速可扩展的进度条,可以在长循环中添加进度提示信息。在阿拉伯语中含义是“进步”,在西班牙语中是“我很爱你()”的缩写(将tqdm是可以分配给tqdm一个变量手动控制更新,此时需要在循环结束后关闭该变量。...
- 2023-05-19 18:03华师数据学院·王嘉宁的博客 本文介绍大模型的训练和推理优化技术,包括混合精度训练、分布式训练DeepSpeed、INT8模型量化、参数有效性学习、混合专家训练、梯度检查点、梯度累积、Flash Attention等。
- 2025-03-07 17:58我爱学大模型的博客 最近在看pytorch的东西,于是想问一下deepseek,让其描述完整过程,果然不失所望。Q:怎么用pytorch训练一个模型,并跑起来。A:(下面的文章是ds回答,我用的元宝满血版)使用PyTorch训练并运行一个模型的完整流程...
- 没有解决我的问题, 去提问
