为什么我在gpu上训练模型但是gpu利用率为0且运行速度还是很慢? 模型主要利用的是tensorflow和keras
已经安装了tensorflow-gpu和cuda
收起
TensorFlow 1.4及以上版本应该是支持cuda10.1的
报告相同问题?
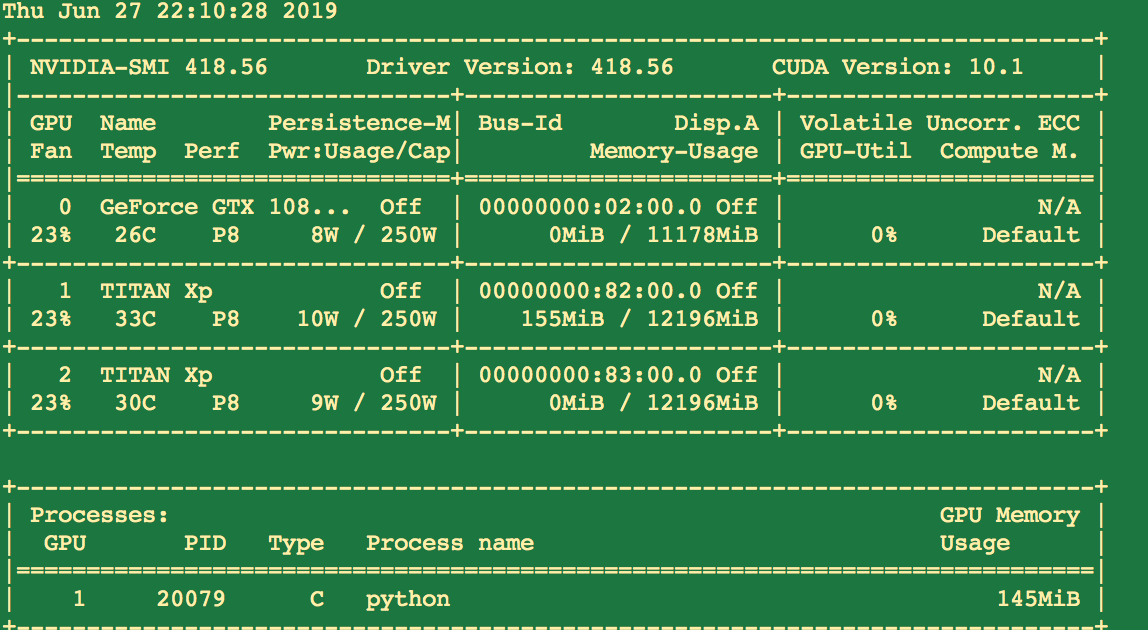

 分享
分享


