在学习文本特征提取,看了篇论文,里面处理的方法是先构建词频表,取词频大于10构建关键词表,再生成向量矩阵:

但是现在我得到嵌套列表统计得到的词频后不知道接下来要怎么弄,数据大概是这个样子
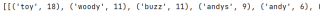
主要是想得到向量矩阵接着学习,请问应该怎么处理呢?

在学习文本特征提取,看了篇论文,里面处理的方法是先构建词频表,取词频大于10构建关键词表,再生成向量矩阵:
但是现在我得到嵌套列表统计得到的词频后不知道接下来要怎么弄,数据大概是这个样子
主要是想得到向量矩阵接着学习,请问应该怎么处理呢?
 分享
分享
按个人理解
1、先筛选出嵌套列表中词频大于10的词
2、制成关键词-序号字典
3、写个简单的one-hot编码函数
import numpy as np
# lst = [[('toy', 18), ('woody', 11), ('buzz', 11), ('andys', 9), ('andy', 6), ...]]
lst_ = [i[0] for j in lst for i in j if i[1] > 10] # 词频大于10的词,这里默认嵌套只有两层
dic = dict(zip(lst_, range(len(lst_)))) # 关键字-序号字典
def convert(s: str):
return np.eye(len(dic))[dic[s]] # 后续可依次传入关键词,对返回结果调用np.r_[result.reshape(1, -1)]合并可得向量矩阵
 创建了问题
3月28日
创建了问题
3月28日




