
python 明明下载了scipy库,但运行显示不能import imread
代码如下,是要弄一个词云
from wordcloud import WordCloud
from scipy.misc import imread
mask=imread('alice.png')
f=open('alice.txt','r',encoding='utf-8')
txt=f.read()
wordcloud=WordCloud(backgound_color='white',\
width=800,\
height=600,\
max_words=200,\
max_font_size=80,\
mask=mask,\
).generate(txt)
wordcloud.to_file('alice_in_wonderland.png')
运行结果如下
Traceback (most recent call last):
File "E:\python\1.py", line 2, in <module>
from scipy.misc import imread
ImportError: cannot import name 'imread'
我明明安装了scipy啊?
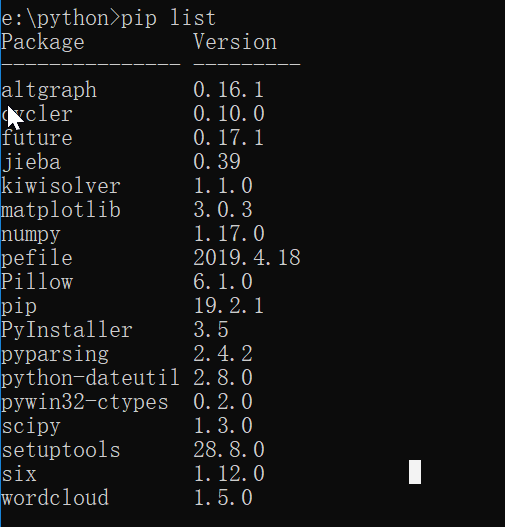
令人头大





