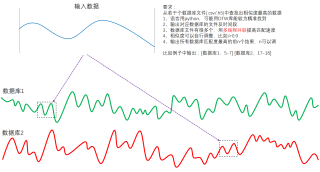
请根据你的数据存储情况修改应用代码中的路径。如果匹配数据文件较多,建议将debug设置为False
# -*- coding: utf-8 -*-
import os, sys, time
import numpy as np
import pandas as pd
from scipy import interpolate
class CurveMatchPipe:
"""时序数据匹配流水线"""
def __init__(self, sample_file, data_folder, max_var=0.1, debug=False):
"""构造函数
sample_file - 样本数据文件名
data_folder - 数据仓库路径
max_var - 偏离方差(数值越小,曲线越相似)
"""
data_csv = self.read_csv(sample_file)
if data_csv is None:
print('样本数据文件%s缺少time列或aim列,程序终止运行。'%sample_file)
sys.exit(1)
stamp, data = self.data_cleaning(*data_csv, 'linear')
self.sample = (data - data.mean()) / data.std()
self.data_folder = data_folder
self.max_var = max_var
self.debug = debug
self.time_cost = list()
self.result = {
'数据文件': list(),
'起始时间': list(),
'截止时间': list(),
'起始索引': list(),
'截止索引': list(),
'偏离方差': list()
}
def read_csv(self, fn):
"""读取数据文件,返回时间戳数组和aim数组"""
stamp, data = list(), list()
with open(fn, 'r') as fp:
lines = fp.readlines()
col_names = lines[0].split(',')
if 'time' in col_names:
idx_time = col_names.index('time')
else:
return None
if 'aim' in col_names:
idx_aim = col_names.index('aim')
else:
return None
for line in lines[1:]:
items = line.split(',')
stamp.append(int(items[idx_time]))
data.append(float(items[idx_aim]))
return np.array(stamp), np.array(data)
def is_continuous(self, stamp):
"""判断时间戳是否连续"""
return np.where(np.diff(stamp) != 1)[0].shape[0] == 0
def data_cleaning(self, stamp, data, method='linear'):
"""数据清洗。对于缺值数据默认线性插值,可选样条插值(cubic)"""
if self.is_continuous(stamp):
return stamp, data
f = interpolate.interp1d(stamp, data, kind=method)
stamp_new = np.linspace(stamp[0], stamp[-1], stamp[-1]-stamp[0]+1)
data_new = f(stamp_new)
return np.int32(stamp_new), data_new
def match(self):
"""遍历数据仓库,匹配样本数据"""
for fn in os.listdir(self.data_folder):
t0 = time.time()
if self.debug:
print('正在处理文件%s...'%fn, end='')
if os.path.splitext(fn)[1] != '.csv':
if self.debug:
print('忽略:文件格式错误')
continue
data_csv = self.read_csv(os.path.join(self.data_folder, fn))
if data_csv is None:
if self.debug:
print('忽略:缺少time列或aim列')
continue
stamp, data = self.data_cleaning(*data_csv, 'linear')
m, n = self.sample.shape[0], data.shape[0]
d = np.vstack([data[i:n-m+1+i] for i in range(m)]).T
d_mean = d.mean(axis=1).reshape(-1,1)
d_std = d.std(axis=1).reshape(-1,1)
d = (d - d_mean) / d_std
diff = d - self.sample
variance = diff.var(axis=1)
for idx in np.argsort(variance):
if variance[idx] > self.max_var:
break
self.result['数据文件'].append(fn)
self.result['起始时间'].append(stamp[idx])
self.result['截止时间'].append(stamp[idx+m])
self.result['起始索引'].append(idx)
self.result['截止索引'].append(idx+m)
self.result['偏离方差'].append(variance[idx])
if self.debug:
print('完成')
t1 = time.time()
self.time_cost.append(t1-t0)
def report(self, out_file=None):
"""打印DataFrame结构的匹配结果报告,若提供输出文件名,则生成excel文件"""
report = pd.DataFrame(self.result)
n = len(self.time_cost)
total = sum(self.time_cost)
mean = total/n
if out_file:
report.to_excel(out_file, sheet_name='匹配结果')
else:
print('---------------------------------------------------------------------------------')
print(report)
print('---------------------------------------------------------------------------------')
print('共计处理%d个数据文件,累计耗时%.3f秒,单个文件平均用时%.3f秒'%(n, total, mean))
if __name__ == '__main__':
cmp = CurveMatchPipe('data/samples/data.csv', 'data/storehouse', max_var=0.3, debug=True)
cmp.match()
cmp.report('report.xlsx')