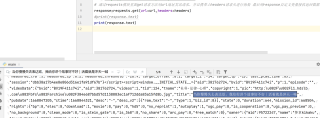
正则表达式去提取网页标题内容,为什么会报错, 跟着B站上面的教程一模一样写的, 到底哪里错了, 我找不到原因, 请大家告诉我原因和思路;
只知道是【title = re.findall('"title":"(.*?)","pubdate"',response.text)[0]】这一行错了
请问如何更改才能提取到我想要的标题(还是用正则表达式),谢谢各位!!
import requests
import re
headers伪装 模拟浏览器
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"}
确定发送请求网址
url='https://www.bilibili.com/video/BV19F411c74i'
通过requests模块里面get请求方法
response=requests.get(url=url,headers=headers)
print(response.text)
title = re.findall('"title":"(.*?)","pubdate"',response.text)[0]
print(title)
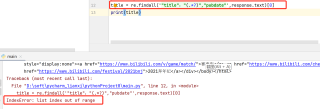
试着把[0]取消,得到的列表里是空的
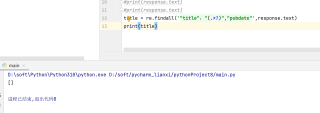
print(response.text)输出的内容有我想要的标题啊,为什么列表会为空呢