同样一张2080Ti,跑30G的bisenet轻轻松松,反而跑十几G的更轻量化的网络就跑不动了,会不会因为深度可分离卷积和非对称卷积这些pytorch没有优化呢? 比如我一张2080ti,512x1024下bisenetv2可以bs=4,反而跑今年TMM一篇flops只有十G的FBSnet 两张2080ti都跑不起?

同样一张2080Ti,跑30G的bisenet轻轻松松,反而跑十几G的更轻量化的网络就跑不动了?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新
- 爱晚乏客游 2022-09-20 15:01关注
原因很多,不知道具体情况不好说。并不是说网络参数越多就一定占用显存越多。
显存是和计算量相关的,并且计算完毕之后这块显存是否释放也有关系的。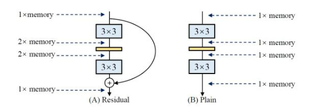
拿ResNet举个例子来说,简单的卷积层计算完output之后就将前面的显存释放掉了,但是如果你想跨层跳跃链接(skip connection),你就得等下面的连接计算完毕才能释放这部分资源,而且分支越多这种资源占用就越久,这还是CNN,要是像RNN的那种开销更大。
另外还有池化,采样这些层是不计算参数量的,但是也要占用显存的啊,越多这种操作就占用越多的显存。
而在数据结构里面,有一招空间换时间的用法,而显卡的并行专门干的就是空间换时间,所以很多模型表面上参数量FLOPS特小,计算和训练都很快,但是这个是用空间换时间,代价就是显存占用高。本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 编辑记录 分享
- 2022-09-20 11:22回答 1 已采纳 原因很多,不知道具体情况不好说。并不是说网络参数越多就一定占用显存越多。显存是和计算量相关的,并且计算完毕之后这块显存是否释放也有关系的。拿ResNet举个例子来说,简单的卷积层计算完output之后
- 2021-06-23 23:12CV51的博客 今天和大家分享CVPR2021中语义分割...随着自动驾驶、视频监控等应用场景的迫切需求,面向终端的轻量化语义分割网络被广泛研究。 为了减少算法的耗时,一些诸如DFANet、BiSeNetV1的语义分割算法使用了轻量化backbone,
- 2021-02-15 16:27钱彬 (Qian Bin)的博客 一、概述 二、算法原理 三、训练 四、部署 4.1 Python本地脚本推理 4.2 基于Django的线上Web部署 4.3 PC端C++部署 4.4 Android端部署
- 2022-09-12 21:47张北海。的博客 在语义分割领域,由于需要对输入图片进行逐像素的分类,运算量很大。通常,为了减少语义分割所产生的计算量,通常而言有两种方式:减小图片大小和降低模型复杂度。减小图片大小可以最直接地减少运算量,但是图像会...
- 2021-04-17 00:223D视觉工坊的博客 点击上方“3D视觉工坊”,选择“星标”干货第一时间送达作者丨happy审稿丨邓富城编辑丨极市平台极市导读本文从HRNet与轻量化网络ShuffleNet的组合出发,针对置换模块存在的计算...
- 2022-02-16 20:16yub4by的博客 """ Created on 2021/1/4 20:25. ...# https://blog.csdn.net/Hanghang_/article/details/108592828 详解bisenet网络结构 # https://blog.csdn.net/TTLoveYuYu/article/details/114372733 详解相关论文 from t...
- 食垚的博客 BiSeNet 已被证明是一种流行的用于实时分割的双流网络。然而,其添加额外路径来编码空间信息的原理是耗时的,并且由于任务特定设计的不足,从预训练任务(例如图像分类)中借用的主干可能无法用于图像分割。为了解决...
- 2023-05-16 00:15林聪木的博客 自适应路由 优化策略 变速推断 基于轻量化深度神经网络的目标检测方法研究 基于深度学习的目标检测方法 深度学习模型压缩的方法 目标检测研究的数据集 基于网络剪枝的目标检测方法 2.1引言 2.2目标检测模型的剪枝 ...
- 2020-05-15 23:34AI算法修炼营的博客 点击上方“AI算法修炼营”,选择“星标”公众号精选作品,第一时间送达01轻量级语义分割基于轻量化网络模型的设计作为一个热门的研究方法,许多研究者都在运算量、参数量和精度之间寻找平衡,希望...
- 2020-07-07 14:16小镇大爱的博客 基于轻量化网络模型的设计作为一个热门的研究方法,许多研究者都在运算量、参数量和精度之间寻找平衡,希望使用尽量少的运算量和参数量的同时获得较高的模型精度。目前,轻量级模型主要有SqueezeNet、MobileNet系列...
- 2021-08-05 02:36BiSeNetV1 和 BiSeNetV2 我对和。 ... 30.49 30.55 31.81 31.73 提示: ss表示单尺度评价, ssc表示单尺度作物评价, msf表示带翻转增强的多尺度评价, mscf表示带翻转评价的多尺度作物评价。
- 2021-07-07 15:29「已注销」的博客 本文将从轻量级网络(MobileNetV2、ShuffleNetV2)、轻量级检测(Light-Head R-CNN、ThunderNet)、轻量级分割(BiSeNet、DFANet)3个方面进行介绍。 轻量级网络 好的论文不仅教你为什么,而且教你怎么做,这两篇论文...
- 2022-08-05 23:26氵文大师的博客 paddle_infer 导出静态图模型,就可以直接用 paddle inference 推理了 上图是我总结的Paddle Inference 中的关键API, 其实接下来可以看到,几乎所有轻量化框架都遵循这里流程: 具体的实验demo, 可以参考...
- 2022-04-18 18:42猴子请来的救兵�的博客 @article{gao2021rethink, title={Rethink Dilated Convolution for Real-time Semantic Segmentation}, author={Gao, Roland}, journal={arXiv preprint arXiv:2111.09957}, ...废话不多说,开局一张图看性能
- 2021-06-02 23:09落花逐流水的博客 经典之作:BiseNet 论文地址:https://arxiv.org/abs/1808.00897.pdf 代码地址:https://github.com/CoinCheung/BiSeNet 本文对之前的实时性语义分割算法进行了总结,发现当前主要有三种加速方法: 1)通过剪裁或 ...
- 2023-10-10 21:44Joney Feng的博客 本文提出了一种新的双边分割网络(BiSeNet)来解决这个问题。我们首先设计了一个具有小步长的空间路径来保留空间信息并生成高分辨率特征。同时,采用快速下采样策略的上下文路径用于获取足够的感受野。在两个路径之...
- 2022-07-25 18:51怪人i命的博客 深度学习中一些轻量的网络模型
- 2020-09-22 23:50Hecttttttttt的博客 轻量级实时语义分割:ICNet & BiSeNet ICNet 贡献 Image Cascade Network Cascade Label Guidance Structure Comparision and Analysis 结果 BiSeNet Introduction Bilateral Segmentation Network NetWork ...
- 2021-05-31 12:48BiSeNet训练自己的数据集,已修改好代码,采用自己的数据集即可训练和测试
- 2021-04-23 16:50AI算法加油站的博客 人脸分割BiseNetV2 模型30多m tf的,cpu版时间80ms,人脸抠图,有的不是特别准。 https://github.com/xuigo/Face_Parsing_BiseNetV2
- 没有解决我的问题, 去提问



问题事件
 系统已结题
10月20日
系统已结题
10月20日 已采纳回答
10月12日
已采纳回答
10月12日-
创建了问题
9月20日
悬赏问题
- ¥15 CST仿真别人的模型结果仿真结果S参数完全不对
- ¥15 误删注册表文件致win10无法开启
- ¥15 请问在阿里云服务器中怎么利用数据库制作网站
- ¥60 ESP32怎么烧录自启动程序
- ¥50 html2canvas超出滚动条不显示
- ¥15 java业务性能问题求解(sql,业务设计相关)
- ¥15 52810 尾椎c三个a 写蓝牙地址
- ¥15 elmos524.33 eeprom的读写问题
- ¥15 用ADS设计一款的射频功率放大器
- ¥15 怎么求交点连线的理论解?