

使用SVM对手写体数字图片分类
import pandas as pd
from sklearn import svm
import joblib
print("1.载入训练数据,对训练数据进行标准化")
train_data = pd.read_csv ('digits_training.csv')
# print(data)
# 分类属性
yTrain = train_data.values[:,0]
# 特征属性
xTrain = train_data.values[:,1:]
# 标准化函数
def normalization(X):
return (X-X.mean())/X.max()
# print("xTrain:{0}".format(xTrain.shape))
# 对特征属性进行标准化处理
xTrain = normalization(xTrain)
# print(xTrain.shape[1])
# print(xTrain.shape)
print("训练数据:",xTrain.shape[0],"条")
# 构建模型
'''
默认核函数是 ‘rbf’-->就是radial basis function keranl (径向基核函数)
模型准确率约为0.89
使用线性核函数(linear)构建模型,准确率在0.908左右
线性核函数主要用于线性可分的情况
在特征数量相对于样本数量非常多的时候,适合采用线性核函数
'''
model = svm.SVC(decision_function_shape='ovo',kernel='linear')
print("2.训练模型……")
model.fit(xTrain,yTrain)
print("3.保存模型……")
joblib.dump(model,"model/svm_classifier_model1.m")
print("4.加载测试数据,对测试数据进行标准化……")
test_data = pd.read_csv("digits_testing.csv")
yTest = test_data.values[:,0]
xTest = test_data.values[:,1:]
print("测试数据:",xTest.shape[0],"条")
xTest = normalization(xTest)
print("5.加载测试好的模型,进行预测……")
model = joblib.load("model/svm_classifier_model1.m")
result =model.predict(xTest)
print("预测错误数据:",(result!=yTest).sum())
print("测试数据正确率:",(result==yTest).sum()/len(yTest))
print("模型内构建正确率估计:",model.score(xTest,yTest))
报错如下:
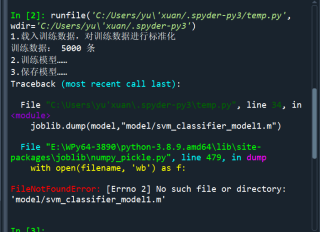
文件夹里的数据集:

'model/svm_classifier_model1.m'这个文件是干嘛的呀?





