

问题遇到的现象和发生背景
部分数据集
d=[[1994.0, 9.6], [1957.0, 9.5], [1997.0, 9.5], [1994.0, 9.4], [1993.0, 9.4], [2012.0, 9.4], [1993.0, 9.4], [1997.0, 9.4], [2013.0, 9.4], [1994.0, 9.4], [2003.0, 9.3], [2016.0, 9.3], [2009.0, 9.3], [2009.0, 9.3], [2008.0, 9.3], [2008.0, 9.3], [1957.0, 9.3], [2008.0, 9.3], [2001.0, 9.2], [2009.0, 9.2], [1931.0, 9.2], [1961.0, 9.2], [2010.0, 9.2], [2004.0, 9.2], [1998.0, 9.2]]
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 计算欧拉距离
def calcDis(dataSet, centroids, k):
clalist=[]
for data in dataSet:
diff = np.tile(data, (k, 1)) - centroids #相减 (np.tile(a,(2,1))就是把a先沿x轴复制1倍,即没有复制,仍然是 [0,1,2]。 再把结果沿y方向复制2倍得到array([[0,1,2],[0,1,2]]))
squaredDiff = diff ** 2 #平方
squaredDist = np.sum(squaredDiff, axis=1) #和 (axis=1表示行)
distance = squaredDist ** 0.5 #开根号
clalist.append(distance)
clalist = np.array(clalist) #返回一个每个点到质点的距离len(dateSet)*k的数组
return clalist
# 计算质心
def classify(dataSet, centroids, k):
# 计算样本到质心的距离
clalist = calcDis(dataSet, centroids, k)
# 分组并计算新的质心
minDistIndices = np.argmin(clalist, axis=1) #axis=1 表示求出每行的最小值的下标
newCentroids = pd.DataFrame(dataSet).groupby(minDistIndices).mean() #DataFramte(dataSet)对DataSet分组,groupby(min)按照min进行统计分类,mean()对分类结果求均值
newCentroids = newCentroids.values
# 计算变化量
changed = newCentroids - centroids
return changed, newCentroids
# 使用k-means分类
def kmeans(dataSet, k):
# 随机取质心
centroids = random.sample(dataSet, k)
# 更新质心 直到变化量全为0
changed, newCentroids = classify(dataSet, centroids, k)
while np.any(changed != 0):
changed, newCentroids = classify(dataSet, newCentroids, k)
centroids = sorted(newCentroids.tolist()) #tolist()将矩阵转换成列表 sorted()排序
# 根据质心计算每个集群
cluster = []
clalist = calcDis(dataSet, centroids, k) #调用欧拉距离
minDistIndices = np.argmin(clalist, axis=1)
for i in range(k):
cluster.append([])
for i, j in enumerate(minDistIndices): #enymerate()可同时遍历索引和遍历元素
cluster[j].append(dataSet[i])
return centroids, cluster
# 创建数据集
def createDataSet():
return d
if __name__=='__main__':
dataset = createDataSet()
centroids, cluster = kmeans(dataset, 3)
print('质心为:%s' % centroids)
print('集群为:%s' % cluster)
for i in range(len(dataset)):
label_pred = estimator.labels_ # 获取聚类标签
# 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="deeppink", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
for j in range(len(centroids)):
plt.scatter(centroids[j][0],centroids[j][1],marker='x',color='red',s=70,label='质心')
plt.show()
运行结果及详细报错内容
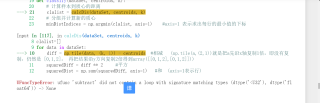
想知道错在哪里,怎么修改






