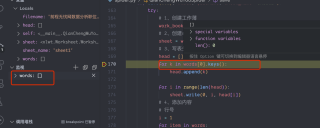
用python做爬虫,代码调来调去一直这样报错,麻烦有没有人看看是怎么回事呀
import urllib.parse
import random
import requests
from lxml import etree
import re
import json
import time
import xlwt
class QianChengWuYouSpider(object):
# 初始化
def __init__(self, city_id, job_type, pages):
# url模板
self.url = 'https://search.51job.com/list/{},000000,0000,00,9,99,{},2,{}.html'
# UA池
self.UApool = [
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:68.0) Gecko/20100101 Firefox/68.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:83.0) Gecko/20100101 Firefox/83.0',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)',
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
]
# 请求头
self.headers = {
'User-Agent': random.choice(self.UApool),
'referer':'https://blog.csdn.net/EricNTH/article/details/104840887',
# 注意加上自己的Cookie
'Cookie': 'guid=5fe585588fded74cf3a82a228c6d9a05; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; search=jobarea%7E%60%7C%21recentSearch0%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%CA%FD%BE%DD%B7%D6%CE%F6%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21; ps=needv%3D0; 51job=cuid%3D222881165%26%7C%26cusername%3Dr1iIYNbsPNRfcePxJ5NnZgEj5wBOs3Lekgry9sYJYfs%253D%26%7C%26cpassword%3D%26%7C%26cname%3D%26%7C%26cemail%3D%26%7C%26cemailstatus%3D0%26%7C%26cnickname%3D%26%7C%26ccry%3D.0wsHycnvu2wI%26%7C%26cconfirmkey%3D%25241%2524G2r4TO2.%25240IZIc4jYqAIuNUJTameNb0%26%7C%26cautologin%3D1%26%7C%26cenglish%3D0%26%7C%26sex%3D%26%7C%26cnamekey%3D%25241%2524fbxj8Rqp%2524c40fEtLHks8SAV1.ooCtW%252F%26%7C%26to%3Ddfb0153b79106f4855f2546b250424b463fd81e5%26%7C%26; sensor=createDate%3D2023-02-28%26%7C%26identityType%3D1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22222881165%22%2C%22first_id%22%3A%2218696373a9a28f-0fa9aef36da24f-74525470-1395396-18696373a9b1537%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fcn.bing.com%2F%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTg2OTYzNzNhOWEyOGYtMGZhOWFlZjM2ZGEyNGYtNzQ1MjU0NzAtMTM5NTM5Ni0xODY5NjM3M2E5YjE1MzciLCIkaWRlbnRpdHlfbG9naW5faWQiOiIyMjI4ODExNjUifQ%3D%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%24identity_login_id%22%2C%22value%22%3A%22222881165%22%7D%2C%22%24device_id%22%3A%2218696373a9a28f-0fa9aef36da24f-74525470-1395396-18696373a9b1537%22%7D; ssxmod_itna=YuD=0KBIqfgGCzDX3G7maa+x0xDqH2Tapve0QIaDla2YxA5D8D6DQeGTbnPsbqzK0DW+aqNhrWhaNt6j+RaCKC8p5L7mDB3DEx06Tq0Ci4GG0xBYDQxAYDGDDpRD84DrD72=ZSUxYPG0DGQD3qGyl4tDA8tDb2=nDiUVDDtOB4G2D7tyfwdY5lbDAMmSY2=DjdTD/+xaZ06oH6aNRLtboh2aiL04xBQD7kiyDYoXUeDH+kNKVOoqm0mxBi4K8gm3BBh4lBmq3DPPfBxttYjXNohxRYh4mIjdWx8DG8GoWrD=; ssxmod_itna2=YuD=0KBIqfgGCzDX3G7maa+x0xDqH2Tapve0QzD6EK40HaRo03PvquXvCnD6eTwm57vlcOFQHyIZL0jeUj2j45maC205xmidt64Rq0C9dA7sGESSyQNuKC8=UnqMhkU7MXqXI9CAp=TiDRi=lcuquCDHLrbtQSKkvWDWGEyDUmBNUpeaTgWb0=c+OBRDrIxwqjA1ExcfQ13sEeMGIfgF1I0vYaG3DQ9iDjKD+ghDD===; partner=sem_pcsogouqg_16633; privacy=1677640570; Hm_lvt_1370a11171bd6f2d9b1fe98951541941=1677557447,1677640568; Hm_lpvt_1370a11171bd6f2d9b1fe98951541941=1677640568; slife=lastlogindate%3D20230301%26%7C%26securetime%3DUGxTZlAxBWZVMQA6CjEPYQczVmI%253D',
}
# 请求参数
self.params = {
"lang": "c",
"postchannel": 0000,
"workyear": 99,
"cotype": 99,
"degreefrom": 99,
"jobterm": 99,
"companysize": 99,
"ord_field": 0,
"dibiaoid": 0,
"line": '',
"welfare": ''
}
# 保存的文件名
self.filename = "前程无忧网" + job_type + "职位信息.xls"
# 城市编号
self.city_id = city_id
# 职位名称 【转为urlencode编码】
self.job_type = urllib.parse.quote(job_type)
# 页数
self.pages = pages
# 临时存储容器
self.words = []
# 请求网页
def parse(self, url):
response = requests.get(url=url, headers=self.headers, params=self.params)
# 设置编码格式为gbk
response.encoding = 'gbk'
# 网页源代码
return response.text
# 数据提取
def get_job(self, page_text):
# xpath
tree = etree.HTML(page_text)
job_label = tree.xpath('//script[@type="text/javascript"]')
# 正则表达式
job_str = re.findall('"engine_jds":(.*"adid":""}]),', str(job_label))
# 转换为json类型
data = json.loads(str(job_str).replace("'", "\""))
# 数据提取
for item in data:
# 职位名称
job_name = item['job_name']
# 职位链接
job_href = item['job_href']
# 公司名称
company_name = item['company_name']
# 公司链接
company_href = item['company_href']
# 月薪范围
salary = item['providesalary_text']
# 工作地点
address = item['workarea_text']
# 其他信息
info_list = item['attribute_text']
# 有个别数据不完整, 直接跳过
if len(info_list) < 3:
continue
# 经验要求
experience = info_list[1]
# 学历要求
education = info_list[2]
# 发布日期
update_date = item['updatedate']
# 公司性质
company_type = item['companytype_text']
# 公司福利
job_welf = item['jobwelf']
# 公司行业
company_status = item['companyind_text']
# 公司规模
company_size = item['companysize_text']
self.words.append({
"职位名称": job_name,
"公司名称": company_name,
"月薪范围": salary,
"工作地点": address,
"经验要求": experience,
"学历要求": education,
"发布日期": update_date,
"公司性质": company_type,
"公司福利": job_welf,
"公司行业": company_status,
"公司规模": company_size,
"职位链接": job_href,
"公司链接": company_href,
})
print("该页爬取完成")
# 数据保存
def save(self, words, filename, sheet_name='sheet1'):
try:
# 1、创建工作薄
work_book = xlwt.Workbook(encoding="utf-8")
# 2、创建sheet表单
sheet = work_book.add_sheet(sheet_name)
# 3、写表头
head = []
for k in words[0].keys():
head.append(k)
for i in range(len(head)):
sheet.write(0, i, head[i])
# 4、添加内容
# 行号
i = 1
for item in words:
for j in range(len(head)):
sheet.write(i, j, item[head[j]])
# 写完一行,将行号+1
i += 1
# 保存
work_book.save(filename)
print('数据保存成功')
except Exception as e:
print('数据保存失败', e)
# 主程序
def run(self):
for page in range(1, self.pages + 1):
# 拼接每页url
url = self.url.format(self.city_id, self.job_type, page)
# 请求网页
page_text = self.parse(url)
# 数据提取
self.get_job(page_text)
# 防止爬取过快
time.sleep(random.randint(1, 2))
self.save(words=self.words, filename=self.filename)
if __name__ == '__main__':
# 实例化爬虫对象 全国爬虫职位信息
# city_id:城市编号(上表)
# job_type:职位名称 (尽量精准,爬取到的数据会更贴切)
# pages:页数(自己指定,注意不要超过总页数)
spider = QianChengWuYouSpider(city_id=000000, job_type="数据分析", pages=2)
# 运行主程序
spider.run()
报的错误是这样的