关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
明月醉窗台
2023-03-16 11:43
采纳率: 0%
浏览 14
首页
人工智能
编译ONNX生成。trt时出错
深度学习
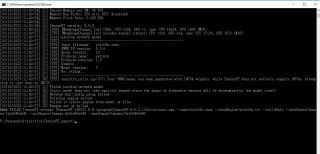
在编译onnx生成.trt模型时,提示生成错误,试了好几次就是不行
求解求解
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
threenewbee
2023-03-16 12:34
关注
模型创建失败了,是不是你的模型定义就有问题
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
ONNX
动态 Shape 导出 +
编译
优化实战指南
2025-04-16 07:06
观熵的博客
> - 如何使用 `
onnx
sim`、`
onnx
runtime`、`TensorRT` 等工具链完成动态 shape 模型的
编译
与性能优化? > - 常见坑点:动态 shape 导出失败、推理
时
报错、性能下降问题的定位与解决路径 > - 多输入、多分辨率、多 ...
[已解决]tensorrt-
trt
exec工具解析网络后停止,.
onnx
无法
生成
.engine文件
2023-06-05 11:09
达达今天学习了嘛的博客
可能是tensorrt下载的是测试版(EA)的原因。把tensorrt版本改成最新的GA版本就好用了。我也不知道怎么弄的,
trt
exec突然不能
生成
.engine文件了。我在网上没有找到相应的解决方法。
ONNX
还适合大模型吗?TensorRT × SmoothQuant 推理加速组合拳实测报告
2025-04-14 21:30
观熵的博客
> 本文围绕“**
ONNX
× TensorRT × SmoothQuant**”三件套,从模型导出到引擎构建,从精度测试到吞吐 benchmark,一步步带你评估这条路线是否适合你的业务场景。 > 是“未来感”的部署解法,还是“还不够成熟”的...
异构硬件平台模型统一
编译
与部署体系构建实战:多引擎兼容、跨架构适配与高效分发全流程解析
2025-05-08 12:30
观熵的博客
随着
人工智能
系统向多终端、多场景、多算力方向演进,企业在实际部署中面临模型版本分裂、推理引擎割裂、平台间格式不兼容等一系列工程难题。传统的单引擎部署模式无法满足 GPU、NPU、CPU、FPGA 等异构设备的高效...
SenseVoice-small
ONNX
量化优势:支持TensorRT加速推理部署教程
2026-01-16 01:42
焦虑中的博客
本文介绍了如何在星图GPU平台上自动化部署sensevoice-small-轻量级多任务语音模型的
ONNX
量化版WebUI V1.0镜像。该平台简化了部署流程,用户可快速搭建基于TensorRT加速的高性能语音识别服务,典型应用场景包括构建...
企业级AI部署标准流程:训练→导出→TensorRT引擎
生成
2025-12-28 03:21
计算机视觉算法的博客
模型训练完成后,直接部署往往性能不...通过
ONNX
导出与TensorRT引擎
生成
,可实现算子融合、精度量化和硬件适配,显著提升推理效率。该流程已在多个生产场景验证,能有效降低延迟、提高吞吐,是AI工业化落地的关键路径。
FaceFusion支持
ONNX
格式导出?跨框架部署更灵活
2025-12-19 13:25
十八像朵花的博客
FaceFusion通过导出为
ONNX
格式...
ONNX
作为开放的模型交换标准,解决了训练框架与推理引擎间的兼容性问题,支持多种硬件和运行
时
环境,提升模型在移动端、Web端及服务端的部署灵活性,并为性能优化和模型安全提供保障。
ONNX
Runtime与TensorRT、CUDA、cuDNN版本兼容性全解析
2025-09-06 03:56
t1u2v的博客
本文深入解析了
ONNX
Runtime与TensorRT、CUDA、cuDNN之间的版本兼容性问题,这是AI模型部署成功的关键前提。文章详细拆解了四大组件的依赖关系,提供了从基础CUDA环境到进阶TensorRT执行提供者的版本对应指南与实战...
从
ONNX
到TensorRT引擎:Python与C++模型转换实战教程
2025-10-23 06:22
sql99的博客
本文详细介绍了如何将
ONNX
模型高效转换为TensorRT引擎,以提升AI模型在生产环境中的推理性能。教程涵盖Python与C++两种主流实现方式,包括环境搭建、模型解析、引擎构建及性能调优等核心步骤,并重点解析了TensorRT...
pytorch模型转tensorrt,pad报错,opset11
2022-10-11 14:30
有来有去9527的博客
2]) [10/10/2022-17:50:38] [E] Failed to parse
onnx
file 问题定位 通过
编译
onnx
-tensorrt工程,直接使用
onnx
trt
程序进行模型转化调试,发现当pytorch转
onnx
采用opset11
时
,pad层的信息为: 也即是,pad层有三个...
图像
生成
模型加速利器:NVIDIA TensorRT深度评测
2025-12-27 23:07
徐校长的博客
NVIDIA TensorRT通过层融合、半精度推理与内核调优,显著提升Stable Diffusion等模型的推理速度,实测U-Net耗
时
下降超60%,整体
生成
进入秒级
时
代,助力高并发AI服务部署。
如何用TensorRT支持长文本
生成
场景?
2025-12-28 04:01
大数据无毛兽的博客
通过KV Cache管理、动态形状支持和算子融合,TensorRT显著提升大模型在长文本
生成
中的推理效率。实测显示首token延迟降低超50%,解码吞吐提升近4倍,支持更长上下文与高并发部署,是工业级LLM落地的关键技术。
AI应用架构师的AI模型优化策略深度剖析
2025-09-07 23:01
AI大模型应用之禅的博客
AI模型优化不是“为了优化而优化”,而是以“落地需求”为导向——解决“延迟高、体积大、成本高”的问题。数据优先:好的数据能让模型用更少参数达到更好效果;结构高效:选择轻量级模型,从根源减少资源消耗;压缩...
PyTorch 2.7模型转换:
ONNX
/TensorRT环境预配置
2026-01-20 00:20
GarnetLynx45的博客
本文介绍了基于星图GPU平台自动化部署PyTorch 2.7镜像的完整流程,该镜像预集成
ONNX
与TensorRT,支持一键完成模型转换与优化。用户可快速将PyTorch模型转为高性能TensorRT引擎,典型应用于边缘设备上的AI推理加速,...
BERT 模型到 TensorRT 的转换
2023-08-04 08:48
初岘的博客
2. 在转为TensorRT模型
时
,可以适当调整最大batchsize、workspace大小等参数,以取得最佳的性能。2. 获取预训练BERT模型:可以直接下载官方提供的PyTorch模型,或训练自定义BERT模型。1. 模型转换要注意输入输出格式的...
AI应用架构师的布局:AI驱动的混合现实应用生态
2025-09-16 01:05
数据架构师的AI之路的博客
当你戴着MR头盔站在工厂车间,...当你在课堂上戴上MR眼镜,历史课本里的兵马俑突然“活”了过来,不仅能回答你的问题,还能演示秦代的兵器制造流程——这不是科幻场景,而是AI驱动的混合现实(MR)生态正在实现的未来。
应急预案演练:当TensorRT引擎加载失败
时
该怎么办?
2025-12-28 06:51
王小约的博客
有效的应急预案应包含自动重建与降级执行机制:优先尝试加载预
编译
引擎,失败后基于
ONNX
模型重建,再失败则切换至
ONNX
Runtime等通用后端维持服务。通过元数据校验、健康检查与CI/CD集成,可实现故障预防与自愈,...
客户决策辅助:
TRT
优化投入产出比测算工具
2025-12-28 04:13
谢兴豪的博客
NVIDIA TensorRT通过模型压缩、算子融合和硬件适配,显著提升AI推理性能与资源利用率。结合实战代码与企业案例,展示其在降低延迟、节省成本和稳定服务方面的关键价值,助力团队科学评估投入产出比。
大规模token
生成
平台架构设计:核心依赖PyTorch-CUDA-v2.7
2025-12-29 14:19
语嫣凝冰的博客
大规模token
生成
系统依赖稳定的底层环境,PyTorch-CUDA-v2.7镜像通过软硬协同优化,解决了版本冲突、性能瓶颈和部署不一致等核心问题。它预集成CUDA、cuDNN、NCCL等组件,支持混合精度、动态批处理与多卡训练,显著...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
3月16日

 分享
分享 创建了问题
3月16日
创建了问题
3月16日


