main_rcv1:
import numpy as np
from scipy.io import savemat
import os
import data
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
#%%
class_0, class_1 = ['C22'], ['C23']
categories = sorted(class_0 + class_1)
sparsity_b1, sparsity_b2 = 0.1, 0.002
sparsity_b1, sparsity_b2 = 0.01, 0.001
num_words = 30
save_to = f'../matlab/data/rcv1/data.mat'
print(save_to)
#%%
dataset = data.TextRCV1(data_dir='./data/RCV1', subset='all', categories=categories)
dataset.clean_text(num='substitute')
dataset.vectorize(stop_words='english')
dataset.remove_short_documents(nwords=50, vocab='full')
dataset.remove_encoded_images()
dataset.remove_frequent_words(sparsity_b1=sparsity_b1, sparsity_b2=sparsity_b2)
dataset.keep_top_words(num_words, 0)
dataset.remove_short_documents(nwords=5, vocab='selected')
dataset.compute_tfidf()
dataset.data_info(show_classes=True)
tfidf = dataset.tfidf.astype(float).T.toarray() # size: (num of words) x (num of documents)
print('max/min tfidf', np.max(tfidf), np.min(tfidf[tfidf > 0]))
card = np.sum(tfidf > 0, 1)
print('max/min edge cardinality', max(card), min(card))
#%%
index2class = {i: dataset.class_names[i] for i in range(len(dataset.class_names))}
true_classes = np.array([int(index2class[i] in class_1) for i in dataset.labels])
#%%
data_mat = {'R': tfidf, 'y': true_classes}
savemat(save_to, data_mat)
data:
import re
import sklearn
from sklearn import *
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
import numpy as np
import os
from tqdm.auto import tqdm, trange
from scipy.sparse import csr_matrix
import random
def balance_class_idx(labels, n_per_class=None):
lset = np.unique(labels)
num_class = [np.sum(labels==ll) for ll in lset]
small_num = np.min(num_class)
n_per_class = small_num if n_per_class is None else n_per_class
lim_lo = min(small_num, n_per_class)
idx = np.arange(len(labels))
idx_sample = []
for li,ll in enumerate(lset):
bi = labels==ll
ni = num_class[li]
idx_s = idx[bi][np.random.RandomState(li).permutation(ni)[:lim_lo]]
idx_sample.append(idx_s)
return np.hstack(idx_sample)
class TextDataset(object):
def clean_text(self, num='substitute'):
""" Transform text to a-z (lowercase) and (single) whitespace. """
for i, doc in enumerate(self.documents):
if num == 'spell':
doc = doc.replace('0', ' zero ')
doc = doc.replace('1', ' one ')
doc = doc.replace('2', ' two ')
doc = doc.replace('3', ' three ')
doc = doc.replace('4', ' four ')
doc = doc.replace('5', ' five ')
doc = doc.replace('6', ' six ')
doc = doc.replace('7', ' seven ')
doc = doc.replace('8', ' eight ')
doc = doc.replace('9', ' nine ')
elif num == 'substitute':
doc = re.sub('(\\d+)', ' NUM ', doc)
elif num == 'remove':
doc = re.sub('[0-9]', ' ', doc)
doc = doc.replace('$', ' dollar ')
doc = doc.lower()
doc = re.sub('[^a-z]', ' ', doc)
doc = ' '.join(doc.split())
self.documents[i] = doc
def vectorize(self, **params):
""" params: stop_words=None ('english') """
vectorizer = CountVectorizer(**params)
self.data = vectorizer.fit_transform(self.documents)
self.vocab = vectorizer.get_feature_names()
assert len(self.vocab) == self.data.shape[1]
def compute_tfidf(self):
tf_transformer = TfidfTransformer().fit(self.data) # norm='l2' ('l1', 'l2')
self.tfidf = tf_transformer.transform(self.data)
def class_conditional_word_dist(self, Mprint=20):
""" class conditional word distribution """
self.class_word_dist = np.array(np.vstack([self.data[self.labels == ci, :].sum(0)/self.data[self.labels == ci, :].sum() for ci in np.unique(self.labels)])) # num of classes x num of words
self.labels_word = self.class_word_dist.argmax(0)
for i in range(self.class_word_dist.shape[0]):
print('top {} frequent words in class {}'.format(Mprint, i))
idx = np.argsort(self.class_word_dist[i, :])[::-1][:Mprint]
for j in range(Mprint):
print(' {:3d}: {:10s} {:.4f}'.format(j, self.vocab[idx[j]], self.class_word_dist[i, idx[j]]))
def data_info(self, show_classes=False):
n, m = self.data.shape
sparsity = self.data.nnz / n / m * 100
print('N = {} documents, M = {} words, sparsity = {:.4f}%'.format(n, m, sparsity))
if show_classes:
for i in range(len(self.class_names)):
num = sum(self.labels == i)
print(' {:5d} documents in class {:2d} ({})'.format(num, i, self.class_names[i]))
def show_document(self, i):
label = self.labels[i]
name = self.class_names[label]
try:
text = self.documents[i]
wc = len(text.split())
except AttributeError:
text = None
wc = 'N/A'
print('document {}: label {} --> {}, {} words'.format(i, label, name, wc))
try:
vector = self.data[i, :]
for j in range(vector.shape[1]):
if vector[0, j] != 0:
print(' {:.2f} "{}" ({})'.format(vector[0, j], self.vocab[j], j))
except AttributeError:
pass
return text
def keep_documents(self, idx):
""" Keep the documents given by the index, discard the others. """
print('{} documents have been removed'.format(self.data.shape[0] - len(idx)))
self.documents = [self.documents[i] for i in idx]
self.labels = self.labels[idx]
self.data = self.data[idx, :]
def keep_words(self, idx):
""" Keep the words given by the index, discard the others. """
print('{} words have been removed'.format(self.data.shape[1] - len(idx)))
self.data = self.data[:, idx]
self.vocab = [self.vocab[i] for i in idx]
def remove_short_documents(self, nwords, vocab='selected'):
""" Remove a document if it contains less than nwords. """
if vocab == 'selected':
# Word count with selected vocabulary.
wc = self.data.sum(axis=1)
wc = np.squeeze(np.asarray(wc))
else: # elif vocab is 'full':
# Word count with full vocabulary.
wc = np.empty(self.data.shape[0], dtype=np.int)
for i, doc in enumerate(self.documents):
wc[i] = len(doc.split())
idx = np.argwhere(wc >= nwords).squeeze()
self.keep_documents(idx)
return wc
def keep_top_words(self, M, Mprint=20):
""" Keep in the vocaluary the M words who appear most often. """
freq = self.data.sum(axis=0)
freq = np.squeeze(np.asarray(freq))
idx = np.argsort(freq)[::-1]
idx = idx[:M]
self.keep_words(idx)
print('most frequent words')
for i in range(Mprint):
print(' {:3d}: {:10s} {:6d} counts'.format(i, self.vocab[i], freq[idx][i]))
return freq[idx]
def sample_words(self, M):
m = self.data.shape[1]
idx = random.sample(set(np.arange(m)), M)
self.keep_words(idx)
def remove_frequent_words(self, sparsity_b1=0.2, sparsity_b2=0.002):
""" words that appear in over a certain fraction of the data-sets are removed. """
freq = self.data.astype(bool).sum(axis=0)
freq_ratio = np.squeeze(np.asarray(freq))/self.data.shape[0]
idx = [i for i, fr in enumerate(freq_ratio) if sparsity_b1 >= fr >= sparsity_b2]
self.keep_words(idx)
return freq_ratio[idx]
def normalize(self, norm='l2'):
data = self.data.astype(np.float64)
self.data = sklearn.preprocessing.normalize(data, axis=1, norm=norm)
def remove_encoded_images(self, freq=1e3):
widx = self.vocab.index('ax')
wc = self.data[:, widx].toarray().squeeze()
idx = np.argwhere(wc < freq).squeeze()
self.keep_documents(idx)
return wc
class Text20News(TextDataset):
def __init__(self, **params):
"""
params:
subset='train' ('train', 'test', 'all')
categories=None (list of category names to load)
shuffle=True (bool)
random_state=42 (int)
remove=() (tuple, subset of ('headers', 'footers', 'quotes'))
categories:
'alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc'
"""
dataset = datasets.fetch_20newsgroups(**params)
self.documents = dataset.data
self.labels = dataset.target
self.class_names = dataset.target_names
assert max(self.labels) + 1 == len(self.class_names)
n, c = len(self.documents), len(self.class_names)
print('N = {} documents, C = {} classes'.format(n, c))
"""
ref:
https://github.com/mdeff/cnn_graph/blob/master/rcv1.ipynb
https://github.com/XifengGuo/DEC-keras/blob/2438070110b17b4fb9bc408c11d776fc1bd1bd56/datasets.py
http://www.ai.mit.edu/projects/jmlr/papers/volume5/lewis04a/lyrl2004_rcv1v2_README.htm
"""
class TextRCV1(TextDataset):
def __init__(self, data_dir='./data/RCV1', subset='all', categories=None):
"""
params:
data_dir='./data/RCV1' download dataset ref: https://github.com/XifengGuo/DEC-keras/blob/2438070110b17b4fb9bc408c11d776fc1bd1bd56/data/reuters/get_data.sh
subset='all' ('train', 'test', 'all')
categories=None (list of category names to load)
level categories:
1st_levl:{'CCAT', 'GCAT', 'MCAT', 'ECAT'}
2nd_level:{'C11','C12','C13','C14','C15','C16','C17','C18','C21','C22','C23','C24',
'C31','C32','C33','C34','C41','C42','E11','E12','E13','E14','E21','E31',
'E41','E51','E61','E71','G15','GCRIM','GDEF','GDIP','GDIS','GENT','GENV',
'GFAS','GHEA','GJOB','GMIL','GOBIT','GODD','GPOL','GPRO','GREL','GSCI',
'GSPO','GTOUR','GVIO','GVOTE','GWEA','GWELF','M11','M12','M13','M14'}
"""
did_to_cat = {}
with open(os.path.join(data_dir, 'rcv1-v2.topics.qrels')) as fin:
for line in fin.readlines():
line = line.strip().split(' ')
cat = line[0]
did = int(line[1])
if cat in categories:
did_to_cat[did] = did_to_cat.get(did, []) + [cat]
# keep only the single-label ones
did_to_cat = {k: v for k, v in did_to_cat.items() if len(v) == 1}
dat_list = ['lyrl2004_tokens_test_pt0.dat',
'lyrl2004_tokens_test_pt1.dat',
'lyrl2004_tokens_test_pt2.dat',
'lyrl2004_tokens_test_pt3.dat',
'lyrl2004_tokens_train.dat']
if subset == 'train':
dat_list = dat_list[-1:]
elif subset == 'test':
dat_list = dat_list[:-1]
data = []
target = []
cat_to_cid = dict(zip(categories, list(range(len(categories)))))
for dat in dat_list:
with open(os.path.join(data_dir, dat)) as fin:
fin_lines = fin.readlines()
for li, line in enumerate(fin_lines):
# print(li, line)
if line.startswith('.I'):
did = int(line.strip().split(' ')[1])
elif line.startswith('.W'):
doc = ''
elif line != '\n':
doc += line
else: # blank line
assert doc != '' # stacked doc
if did in did_to_cat: # append to data and target lists
data.append(doc)
target.append([cat_to_cid[d] for d in did_to_cat[did]])
# print((len(data), 'and', len(did_to_cat)))
# assert len(data) == len(did_to_cat)
self.documents = data
self.labels = np.array(target).flatten() # single label
self.class_names = categories
# self.cvt_labels_onehot() # labels as array
if isinstance(self.labels, list):
assert max(sum(self.labels, [])) + 1 == len(self.class_names)
else:
assert max(self.labels) + 1 == len(self.class_names)
n, c = len(self.documents), len(self.class_names)
print('N = {} documents, C = {} classes'.format(n, c))
def cvt_labels_onehot(self, idx):
n, c = len(self.documents), len(self.class_names)
labels = np.zeros((len(idx), c), dtype=bool)
print('converting label names to mat...')
for i, ni in enumerate(trange(idx)):
labels[i, self.labels[ni]] = True
self.labels_onehot = csr_matrix(labels)
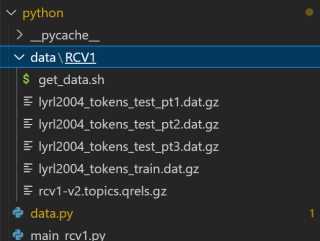
这是我在GitHub上找的一段代码但是我用相对路径和绝对路径都报错了,找不到原因。
Traceback (most recent call last):
File "d:\program\hg_general_submodular_weights-main\hg_general_submodular_weights-main\python\main_rcv1.py", line 21, in <module>
dataset = data.TextRCV1(data_dir='./data/RCV1', subset='all', categories=categories)
File "d:\program\hg_general_submodular_weights-main\hg_general_submodular_weights-main\python\data.py", line 233, in __init__
with open(os.path.join(data_dir, 'rcv1-v2.topics.qrels')) as fin:
FileNotFoundError: [Errno 2] No such file or directory: './data/RCV1\\rcv1-v2.topics.qrels'
这是我的文件路径: