以鸢尾花数据为例,完成机器学习算法代码编写
1)导入数据并查看
2)对数据进行转换
3)实施特征选择,并对比PCA
4)选择合适的算法
5)超参数调优
6)可视化模型成效
7)可视化模型评估指标
8)使用模型预测

不会,但是想知道,希望我能看懂吧

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

 关注
关注【相关推荐】
- 你看下这篇博客吧, 应该有用👉 :图像处理合集:图像基础操作(图像翻转、图像锐化、图像平滑等)、图像阈值分割(边缘检测、迭代法、OSTU、区域增长法等)、图像特征提取(图像分割、灰度共生矩阵、PCA图像压缩)
- 除此之外, 这篇博客: 使用PCA降维实现鸢尾花数据特征可视化中的 4.可视化 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
#要将三种鸢尾花的数据分布显示在二维平面坐标系中,对应的两个坐标(两个特征向量)应该是三种鸢尾花降维后的x1和x2,取出三种鸢尾花下不同的x1和x2 X_dr[y == 0, 0] #这里是布尔索引 #要展示三中分类的分布,需要对三种鸢尾花分别绘图 #可以写成三行代码,也可以写成for循环 """ plt.figure() plt.scatter(X_dr[y==0, 0], X_dr[y==0, 1], c="red", label=iris.target_names[0]) plt.scatter(X_dr[y==1, 0], X_dr[y==1, 1], c="black", label=iris.target_names[1]) plt.scatter(X_dr[y==2, 0], X_dr[y==2, 1], c="orange", label=iris.target_names[2]) plt.legend() plt.title('PCA of IRIS dataset') plt.show() """ colors = ['red', 'black', 'orange'] iris.target_names plt.figure() for i in [0, 1, 2]: plt.scatter(X_dr[y == i, 0] ,X_dr[y == i, 1] ,alpha=.7#指画出的图像的透明度 ,c=colors[i] ,label=iris.target_names[i] ) plt.legend()#图例 plt.title('PCA of IRIS dataset') plt.show()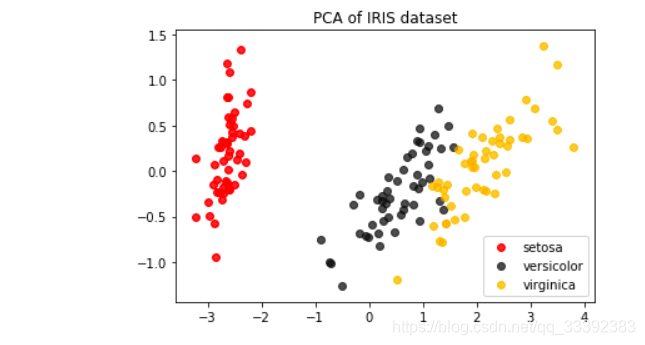
鸢尾花的分布被展现在我们眼前了,明显这是一个分簇的分布,并且每个簇之间的分布相对比较明显,也许versicolor和virginia这两种花之间会有一些分类错误,但setosa肯定不会被分错。这样的数据很容易分类,可以预见,KNN,随机森林,神经网络,朴素贝叶斯,Adaboost这些分类器在鸢尾花数据集上,未调整的时候都可以有95%上下的准确率。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2020-04-24 09:14沉默王二的博客 本篇文章来和大家聊聊自学编程中的一些误区——这是我在 B 站上看了羊哥的一期视频后有感而发的文章。因为确实有很多读者也曾私信问过我这些方面的问题,很有代表性,所以我就结合自己的亲身体会来谈一谈,希望对小...
- 2024-01-03 14:24这就是编程的博客 原文:LLMs and Programming in the first days of 2024首先我要明确,这篇文章并不旨在回顾大语言模型。显而易见,2023 年对人工智能来说是不平凡的一年,再去强调这一点似乎没有多大必要。这篇文章更多是作为一位...
- 2021-04-12 18:331_bit的博客 此系列将会持续更新,包括别的语言以及实战都将使用对话的方式进行教学,基础编程语言教学适用于零基础小白,之后实战课程也将会逐步更新。 若有想学习的内容可以在评论区留言,根据大家的要求持续更新。点赞过十万...
- 2021-03-16 11:171_bit的博客 此系列将会持续更新,包括别的语言以及实战都将使用对话的方式进行教学,基础编程语言教学适用于零基础小白,之后实战课程也将会逐步更新。 若有想学习的内容可以在评论区留言,根据大家的要求持续更新。点赞过十万...
- 2021-04-06 09:441_bit的博客 此系列将会持续更新,包括别的语言以及实战都将使用对话的方式进行教学,基础编程语言教学适用于零基础小白,之后实战课程也将会逐步更新。 若有想学习的内容可以在评论区留言,根据大家的要求持续更新。点赞过十万...
- 2021-03-18 10:101_bit的博客 此系列将会持续更新,包括别的语言以及实战都将使用对话的方式进行教学,基础编程语言教学适用于零基础小白,之后实战课程也将会逐步更新。 若有想学习的内容可以在评论区留言,根据大家的要求持续更新。点赞过十万...
- 2021-07-16 15:04沉默王二的博客 啊,懂了? 只能说,牛逼都在年少。二哥花了一个月的时间,把近十年来读过的一系列计算机经典书籍(戳一戳)))全部都整理出来了,给大家瞧瞧,可以说是包罗万象,应有尽有(入门→工具→框架→数据库→并发编程→...
- 2023-02-04 00:31今天又是充满希望的一天的博客 C++这门语言是一个追求底层的语言, 老实说我为什么选择C++就是因为它够底层, 让我能知道底层大致在干什么。但是在学习的过程很明显存在不具体的问题, 而且C++语言的语法非常多,理解cpp的底层基础上, 结合代码...
- 2021-03-19 13:041_bit的博客 此系列将会持续更新,包括别的语言以及实战都将使用对话的方式进行教学,基础编程语言教学适用于零基础小白,之后实战课程也将会逐步更新。 若有想学习的内容可以在评论区留言,根据大家的要求持续更新。点赞过十万...
- 2021-02-08 17:40咦呀咦呀哟的博客 我们都知道敲代码是程序员每天都干的事情,可是很多人都以为,我英语不好,我不喜欢英语,但我喜欢软件,我能学好吗?答案是肯定的!!!首先,我们学软件要接触到的目前有统计过,实实在在常用的只有476个单词,...
- 2021-03-15 12:081_bit的博客 此系列将会持续更新,包括别的语言以及实战都将使用对话的方式进行教学,基础编程语言教学适用于零基础小白,之后实战课程也将会逐步更新。 若有想学习的内容可以在评论区留言,根据大家的要求持续更新。点赞过十万...
- 2021-03-20 09:201_bit的博客 此系列将会持续更新,包括别的语言以及实战都将使用对话的方式进行教学,基础编程语言教学适用于零基础小白,之后实战课程也将会逐步更新。 若有想学习的内容可以在评论区留言,根据大家的要求持续更新。点赞过十万...
- 2020-08-22 10:37m0_50267869的博客 现在流行的编程语言里,python的热度可谓是热的通红,python以其短小精悍的语法、以其高效的开发,简单入门作为亮点,迅速的在各个领域占有一席之地。 然而,无论你说python有多好,我都不建议你学它入门,其理由...
- 2024-07-18 17:49小尤笔记的博客 很多人在回忆自己的编程学习之路时,都会意识到:我本来完全可以用更快的速度学会编程的。因此,通过反思过去,我总结了一些可能帮助大家提升学习效率的策略,避免盲目苦学,实现更有序、更高效的学习进程。"快速...
- 没有解决我的问题, 去提问

问题事件
 已结题
(查看结题原因) 2月13日
已结题
(查看结题原因) 2月13日-
已采纳回答
2月13日
-
创建了问题
12月25日