LDA主题分析出来一堆乱码,我把原文本xlsx文件已经导出为csv,格式为utf-8,为啥还会出现这种问题
而且读取的时候有注意用encoding='utf-8'
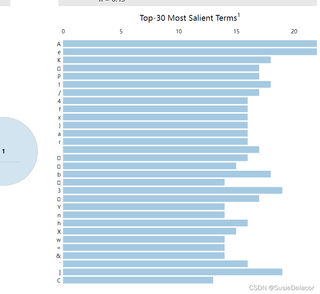

LDA主题分析出来一堆乱码,我把原文本xlsx文件已经导出为csv,格式为utf-8,为啥还会出现这种问题
而且读取的时候有注意用encoding='utf-8'
 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
在进行LDA(Latent Dirichlet Allocation)主题模型分析时,如果你遇到乱码问题,这通常是因为文本数据中的字符编码不正确。解决这个问题的一般步骤包括检查数据编码、转换编码以及确保所有处理过程都使用正确的编码。下面是针对你的问题的具体解决方案:
chardet来检测文件的编码。import chardet
def detect_encoding(file_path):
with open(file_path, 'rb') as f:
result = chardet.detect(f.read())
return result['encoding']
encoding = detect_encoding('your_file.csv')
print("Detected encoding:", encoding)
codecs库的open函数并指定'utf-8'作为解码方式读取文件,然后写入新的CSV文件。import codecs
def convert_encoding(input_file, output_file):
with codecs.open(input_file, 'r', encoding=detect_encoding(input_file)) as in_file:
content = in_file.readlines()
with codecs.open(output_file, 'w', encoding='utf-8') as out_file:
out_file.writelines(content)
convert_encoding('your_original_file.csv', 'your_converted_file.csv')
pandas库来操作DataFrame,并使用nltk库进行文本预处理。import pandas as pd
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from collections import defaultdict
import string
# 加载停用词
nltk.download('stopwords')
nltk.download('punkt')
# 定义预处理函数
def preprocess(text):
stop_words = set(stopwords.words('english'))
text = text.lower()
tokens = word_tokenize(text)
filtered_text = [token for token in tokens if token.isalnum()]
filtered_text = [token for token in filtered_text if token not in stop_words]
filtered_text = [token for token in filtered_text if token not in string.punctuation]
return filtered_text
# 读取CSV文件并进行预处理
df = pd.read_csv('your_converted_file.csv', encoding='utf-8')
df['processed_text'] = df['text_column'].apply(preprocess) # 假设你的文本列名为'text_column'
# 将预处理后的文本转换为 Bag of Words (BoW)
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(tokenizer=preprocess)
bow_matrix = vectorizer.fit_transform(df['processed_text'])
from sklearn.decomposition import LatentDirichletAllocation
lda_model = LatentDirichletAllocation(n_components=5, random_state=42) # 可以根据需求调整主题数量
lda_model.fit(bow_matrix)
pyLDAvis库进行可视化。安装这个库(如果还没有安装的话):pip install pyLDAvis gensim
然后进行可视化:
import pyLDAvis.sklearn
import matplotlib.pyplot as plt
lda_vis = pyLDAvis.sklearn.prepare(lda_model, bow_matrix, vectorizer)
pyLDAvis.display(lda_vis)
# 或者保存为HTML文件
pyLDAvis.save_html(lda_vis, 'lda_visualization.html')
这样应该就可以得到一个清晰的主题分布图了。如果你的原始文本是中文的,记得替换掉英文的停用词和分词器,并且可能需要使用专门的中文分词工具,如jieba。
分享 【网络舆情分析】基于C++的多源数据采集与BiLSTM情感分析模型:互联网舆情管理平台设计与可视化实现 项目介绍 基于C++的互联网网络舆情管理与可视化平台设计与实现的详细项目实例(含模型描述及部分示
【网络舆情分析】基于C++的多源数据采集与BiLSTM情感分析模型:互联网舆情管理平台设计与可视化实现 项目介绍 基于C++的互联网网络舆情管理与可视化平台设计与实现的详细项目实例(含模型描述及部分示 修改了问题
4月25日
创建了问题
4月25日
修改了问题
4月25日
创建了问题
4月25日

