使用swintransformer进行图像分类,为什么loss会出现这种情况
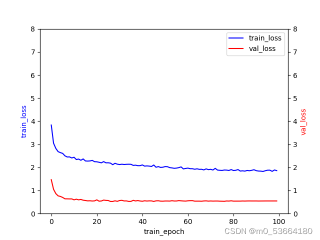

使用swintransformer进行图像分类,为什么loss会出现这种情况
 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
在使用Swin Transformer进行图像分类时,遇到训练过程中损失(Loss)曲线呈现波动或不理想的情况是常见的。这可能是由于多种原因造成的,包括学习率设置不当、模型过拟合、数据增强不足、批处理大小不合适等。以下是针对这些问题的一些建议,帮助您优化训练过程并改善损失情况。
调整学习率: 学习率决定了参数更新的速度。过大可能会导致训练不稳定,而过小则可能导致收敛速度慢。您可以尝试使用学习率调度器,例如余弦退火(Cosine Annealing)、指数衰减或多步衰减等方法,以更好地控制学习率的变化。下面是一个使用PyTorch的示例,采用多步衰减策略:
import torch.optim.lr_scheduler as lr_scheduler
def get_lr_scheduler(optimizer, milestones, gamma=0.1):
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=gamma)
return scheduler
# 假设optimizer是您的优化器, milestones=[40, 60] 表示在第40和60个epoch降低学习率
scheduler = get_lr_scheduler(optimizer, milestones=[40, 60])
正则化与Dropout:
使用权重衰减(L2正则化)可以防止过拟合。在Swin Transformer的构建中,确保在Transformer模块之后添加nn.LayerNorm层,并在训练期间启用它。另外,可以考虑在某些层后加入Dropout层。
from transformers import SwinTransformerFeatureExtractor, SwinTransformerForImageClassification
from transformers import AdamW, get_linear_schedule_with_warmup
model = SwinTransformerForImageClassification.from_pretrained('swin-base-patch4-window12-224')
model.classifier.dropout.p = 0.1 # 设置Dropout概率为0.1
数据增强: 确保您在训练期间使用足够的数据增强技术,如随机翻转、旋转、缩放等。这有助于提高模型泛化能力,减少过拟合。
from torchvision.transforms import transforms
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]),
}
批处理大小: 批处理大小也会影响训练效果。通常情况下,较大的批处理可以提供更好的梯度估计,但需要更多的内存。找到一个适合您硬件的合适大小。
早停法: 如果发现验证集上的性能开始下降,可以使用早停法(Early Stopping),即当验证损失不再下降时停止训练。
模型复杂性: 考虑使用不同规模的Swin Transformer模型,如Swin-Tiny、Swin-Small、Swin-Base和Swin-Large,看看是否能获得更好的结果。
检查输入数据: 确保输入数据正确且格式一致,没有缺失值或异常值。
训练更多/更少的epoch: 根据您的数据量和计算资源,尝试增加或减少训练轮数。
根据上述建议,逐步调整和优化您的训练配置。同时,观察训练和验证损失随时间的变化可以帮助您了解哪些更改对模型性能产生了积极影响。如果您提供了具体的损失曲线图片,我可以为您提供更详细的分析和建议。
分享 006基于小波变换和改进ResNet的噪声环境下滚动轴承故障智能诊断Intelligent fault diagnosis of rolling bearing based on wavelet tr
006基于小波变换和改进ResNet的噪声环境下滚动轴承故障智能诊断Intelligent fault diagnosis of rolling bearing based on wavelet tr 创建了问题
4月26日
创建了问题
4月26日


