
利用深度学习做遥感变化检测,以孪生网络和UNet++为baseline作改进,但随着训练推进,精确度不断上升,召回率却不断下降,即F1得分也会降低,这是什么原因?过拟合还是其他问题?如何解决?
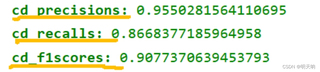
训练到第35轮左右的精确度、召回率、F1得分如下图所示
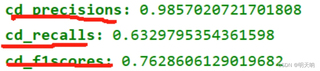
训练到第70轮左右的精确度、召回率、F1得分如下图所示
如果从修改损失函数下手,定向提升网络召回率,该怎么修改,是不是可以对focal loss做了一些改进完成这个需求,比如增加w0,w1,损失权重,就是让模型认为,假阴性(实际存在变化,但被错误地判定为没有变化的情况)的惩罚比假阳性的惩罚更大,参数gamma, alpha,w0, w1应该怎么设置,才能提升召回率,即减少漏检率,请帮忙修改以下损失函数
class FocalLoss(nn.Module):
def __init__(self, gamma=0, alpha=None, size_average=True,w0, w1):
super(FocalLoss, self).__init__()
self.gamma = gamma
self.alpha = alpha
# 调整正负样本权重
self.w0 =
self.w1 =
if isinstance(alpha, (float, int)):
self.alpha = torch.Tensor([alpha, 1-alpha])
if isinstance(alpha, list):
self.alpha = torch.Tensor(alpha)
self.size_average = size_average
def forward(self, input, target):
if input.dim() > 2:
# N,C,H,W => N,C,H*W
input = input.view(input.size(0), input.size(1), -1)
# N,C,H*W => N,H*W,C
input = input.transpose(1, 2)
# N,H*W,C => N*H*W,C
input = input.contiguous().view(-1, input.size(2))
target = target.view(-1, 1)
logpt = F.log_softmax(input,dim=1)
logpt = logpt.gather(1, target)
logpt = logpt.view(-1)
pt = Variable(logpt.data.exp())
if self.alpha is not None:
if self.alpha.type() != input.data.type():
self.alpha = self.alpha.type_as(input.data)
at = self.alpha.gather(0, target.data.view(-1))
logpt = logpt * Variable(at)
loss = -1 * (1-pt)**self.gamma * logpt
if self.size_average:
return loss.mean()
else:
return loss.sum()
除了修改损失函数外,还有什么办法能够解决。





