为什么yolo训练出来的结果和我用混淆矩阵算出来的不一样啊,为什么,这个结果难道不是这样算的吗,有没有友友解答
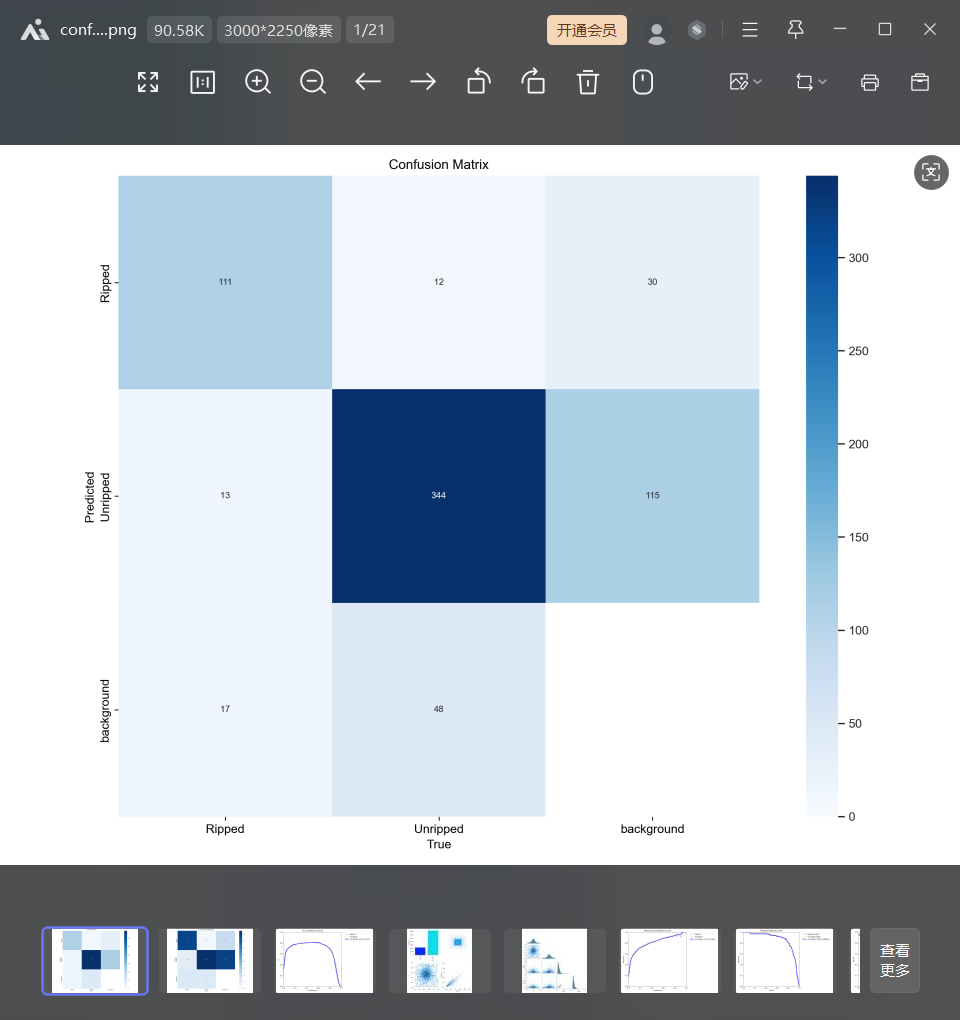


为什么yolo训练出来的结果和我用混淆矩阵算出来的不一样啊,为什么,这个结果难道不是这样算的吗,有没有友友解答
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
你遇到了混淆矩阵计算的问题,这是 YOLO 模型训练中常见的问题。混淆矩阵是计算模型预测结果与真实标签之间的相似度的重要工具。
YOLO 模型训练时,会生成预测结果和真实标签,这两个结果之间的相似度可以用混淆矩阵来计算。混淆矩阵是一个二维矩阵,行表示真实标签,列表示预测结果。每个单元格中的值表示预测结果为该类别的样本中,实际标签为该类别的样本的数量。
如果你发现 YOLO 模型训练出来的结果与你用混淆矩阵算出来的结果不一样,这可能是由于以下原因:
解决这个问题的方法是:
如果你仍然无法解决这个问题,可以提供更多的信息和代码,我将尽力帮助你解决这个问题。
分享 创建了问题
4月25日
创建了问题
4月25日

