刚刚接触,啥也不会,训练了80个epoch了,如果是过拟合的话,应该怎么样去调呢,很崩溃整了好几天了
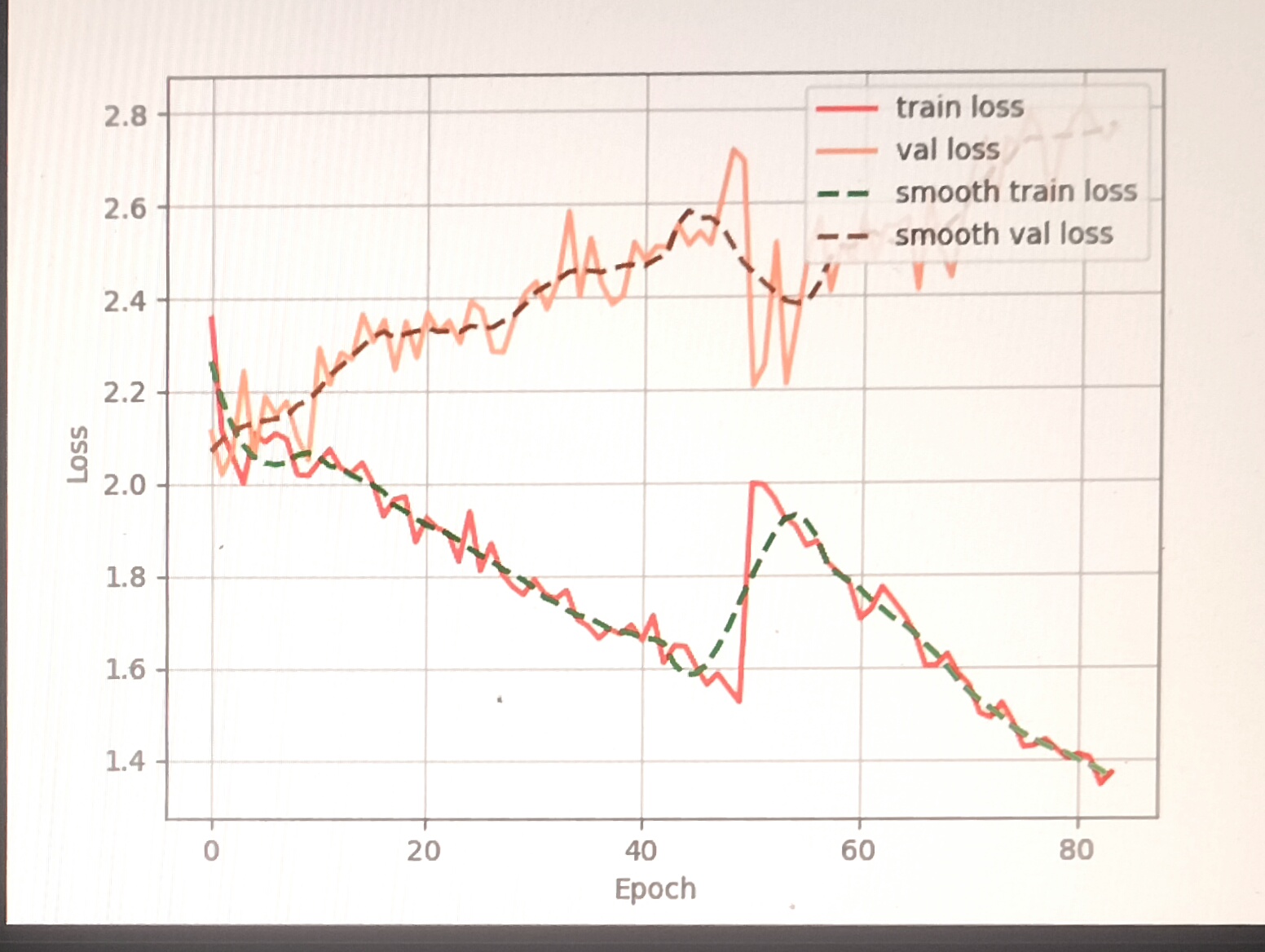

刚刚接触,啥也不会,训练了80个epoch了,如果是过拟合的话,应该怎么样去调呢,很崩溃整了好几天了
 分享
分享
 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以点击头像关注私信或评论。如果答案让您满意,请采纳、点赞、关注,非常感谢!
根据您提供的训练曲线图描述(train loss 和 val loss 变化趋势),以下是专业分析和建议:
从曲线特征来看:
✅ 典型过拟合特征:模型在训练集上表现过优,但泛化能力下降。
# 数据增强示例(PyTorch)
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.ColorJitter(0.1,0.1,0.1) # 颜色抖动
])
# 添加Dropout层(Keras示例)
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5)) # 丢弃50%神经元
# 早停法回调(TensorFlow示例)
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=5, # 连续5轮不改善则停止
restore_best_weights=True
)
# L2正则化(PyTorch示例)
optimizer = torch.optim.Adam(model.parameters(),
lr=0.001,
weight_decay=1e-4) # L2惩罚项
下次训练时建议记录:
💡 从您的描述看,建议优先尝试数据增强+早停法组合,通常能快速改善过拟合现象。如果仍有疑问,可以提供更详细的模型结构或数据信息,我会给出更具体的调参建议。
分享 创建了问题
5月5日
创建了问题
5月5日

