
建立好深度学习的模型后,使用反向传播法进行训练。
定义了训练方式:
model.compile(loss='categorical_crossentropy',
optimizer='adam',metrics=['accuracy'])
执行训练:
train_history =model.fit(x=x_Train_normalize,
y=y_Train_OneHot,validation_split=0.2,
epochs=10,batch_size=200,verbose=2)
执行后出现: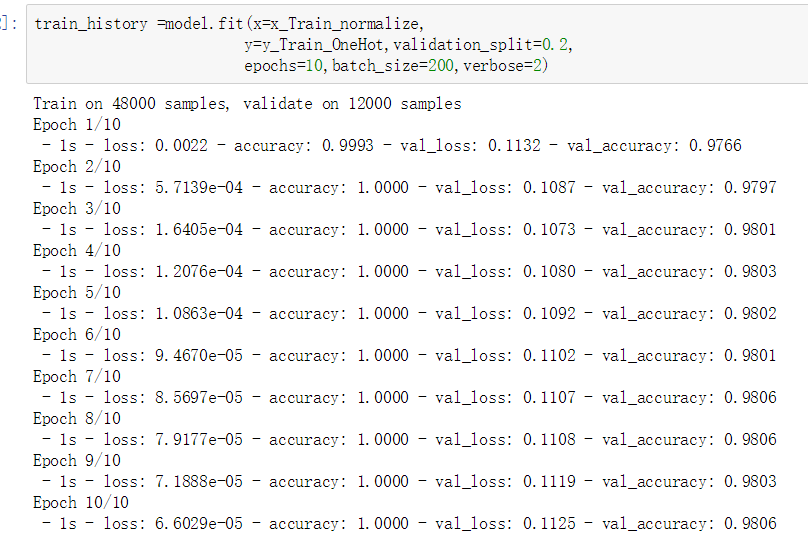
建立show_train_history显示训练过程:
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
画出准确率执行结果:
show_train_history(train_history,'acc','val_acc')
结果出现以下问题: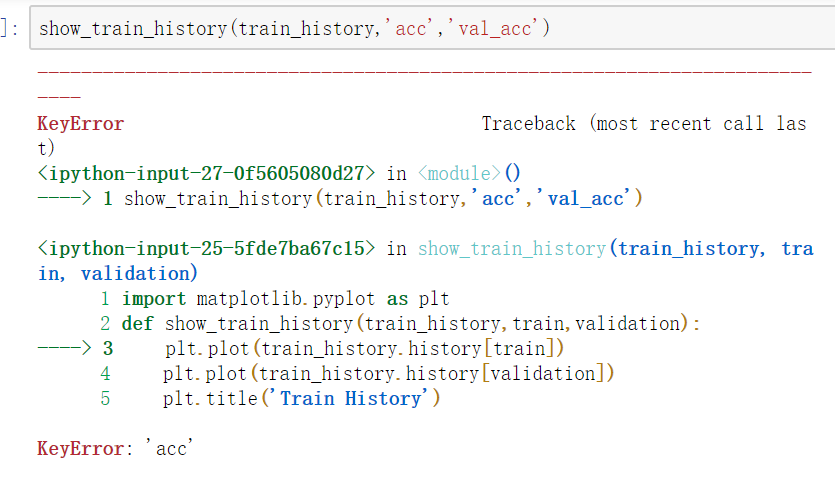
这是怎么回事呀?
求求大佬救救孩子555





