最后一小段我自己觉得收敛了,可是前面那么多波动,这应该怎么办啊,求帮忙看看
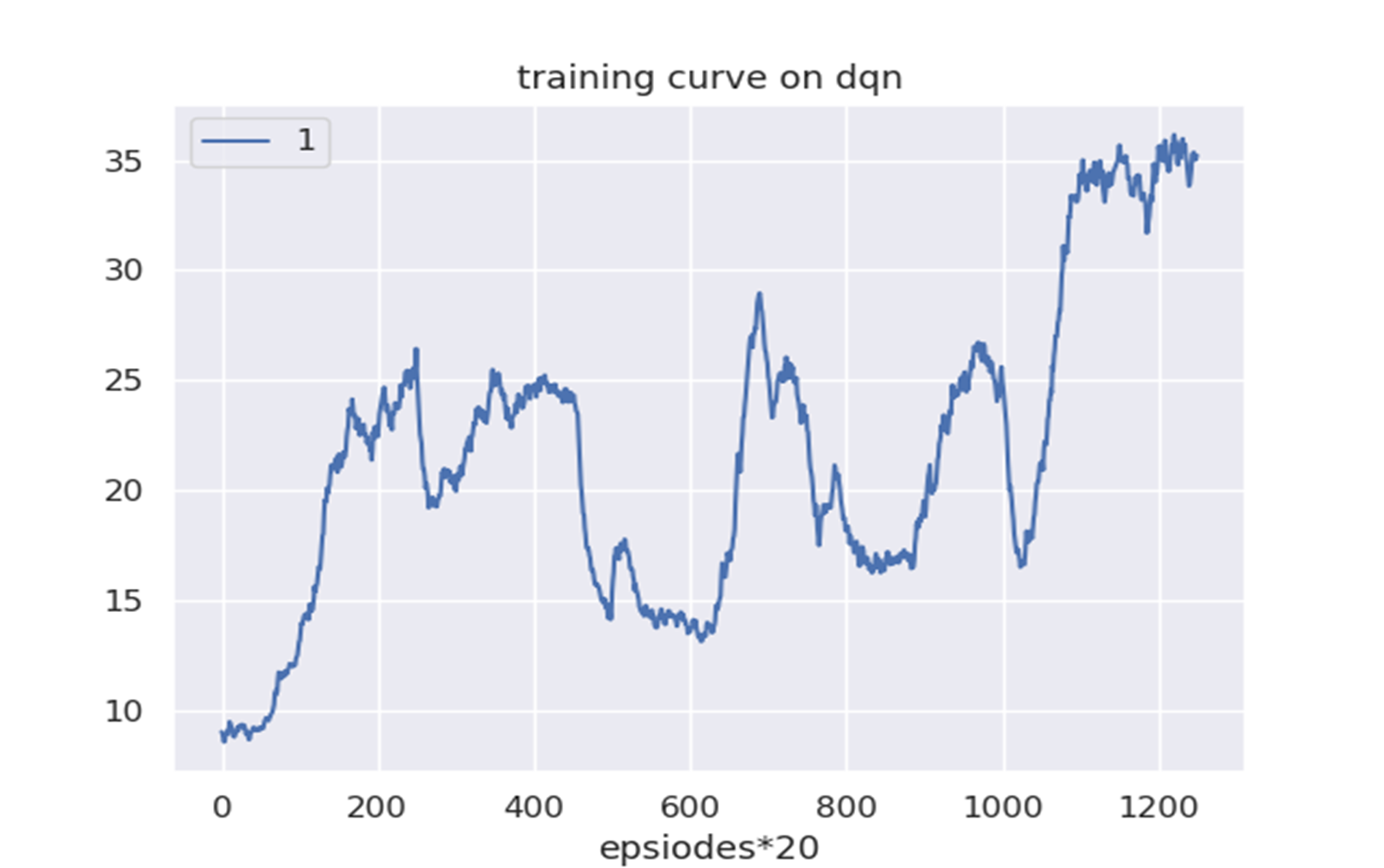

最后一小段我自己觉得收敛了,可是前面那么多波动,这应该怎么办啊,求帮忙看看
 分享
分享
 关注
关注让阿豪来帮你解答,本回答参考chatgpt3.5编写提供,如果还有疑问可以评论或留言题目:如何处理模型训练过程中前面波动后面收敛的情况? 回答:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
自己觉得收敛了,但前面波动较大的情况可能是因为模型一开始参数随机初始化的影响,可以尝试增加训练时的Batchsize,增加数据量,或者调整模型结构等方法来改善。同时,可以监控训练过程中的损失曲线和准确率曲线,及时调整模型训练策略。
分享 系统已结题
9月27日
系统已结题
9月27日 已采纳回答
9月19日
创建了问题
9月19日
已采纳回答
9月19日
创建了问题
9月19日

