下午好🌅🌅🌅
本答案参考通义千问
你提到的问题非常关键,涉及到 YOLOv12 框架下使用不同预训练权重时出现的 训练失败或效果极差 的现象。根据你的描述,可以推测出几个可能的原因,并给出相应的解决方案和代码示例。
一、问题分析
你提到:
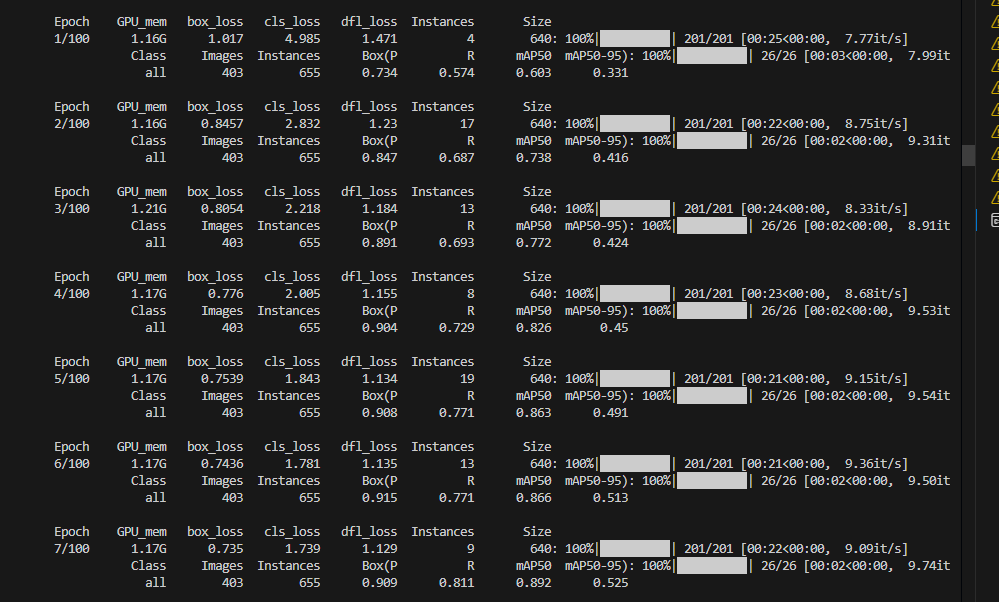
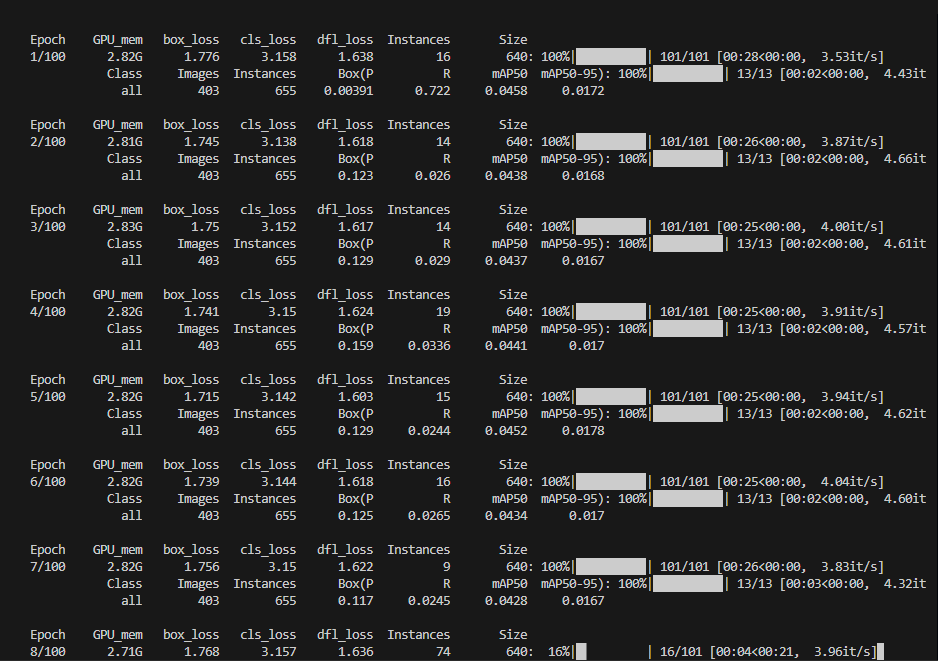
- 用 YOLOv12框架 训练过 YOLOv5 预训练权重后,再用 YOLOv12预训练权重 训练时,mAP50一直维持在0.004左右,没有提升。
- 使用 YOLOv8 或 YOLOv5 的预训练权重时,可以正常训练。
- 你已经尝试了 YOLOv12 的预训练权重,但效果不佳。
这表明:
1. 模型架构与预训练权重不匹配
YOLOv12 的结构可能与 YOLOv5、YOLOv8 不同,导致某些层(如 backbone、neck、head)的权重无法正确加载。
2. 权重文件格式不兼容
YOLOv12 可能使用了不同的权重保存方式(如 .pt、.pth、.bin 等),而你的训练脚本可能没有正确解析这些权重。
3. 训练配置不一致
YOLOv12 和 YOLOv5 的数据增强、损失函数、学习率等参数可能有差异,导致训练不稳定。
二、解决方案
以下是详细的排查与解决步骤:
1. 检查模型架构是否匹配
- 确保你加载的 YOLOv12 预训练权重是与当前模型结构完全一致的。
- 如果你使用的是自定义模型(比如修改了 Backbone 或 Head),那么必须使用相同结构的预训练权重。
✅ 示例:加载权重前验证模型结构
from models.yolo import Model # 假设这是你使用的模型类
# 加载预训练权重
model = Model("your_model.yaml", nc=80) # nc 是类别数
model.load_state_dict(torch.load("yolov12_pretrained.pt"), strict=False)
注意:如果 strict=True,会报错;设置为 False 时会忽略不匹配的层,但可能导致效果不佳。
2. 确认权重文件格式与读取方式一致
- YOLOv12 可能使用了不同的权重保存方式(如 PyTorch 的
.pt 文件)。 - 你需要确保你的训练脚本支持该格式。
✅ 示例:加载 YOLOv12 预训练权重
import torch
# 加载预训练权重
pretrained_weights = torch.load("yolov12_pretrained.pt")
model.load_state_dict(pretrained_weights, strict=False)
如果加载失败,请查看权重文件的结构是否与模型一致。
3. 检查训练配置是否合理
- YOLOv12 可能对输入尺寸、锚框、数据增强等有特定要求。
- 请确保你的
data.yaml、hyp.scaled.yaml 等配置文件与 YOLOv12 的标准配置一致。
✅ 示例:检查 data.yaml
train: ./images/train/
val: ./images/val/
nc: 80
names: ['person', 'bicycle', ...] # 类别列表
4. 调试训练过程中的 loss 和 mAP
- 在训练过程中打印 loss 和 mAP,看是否有异常。
- 如果 loss 一直下降,但 mAP 没有提升,可能是 目标检测任务中正样本太少或标签错误。
✅ 示例:在训练循环中添加日志
for epoch in range(epochs):
for batch in train_loader:
images, labels = batch
outputs = model(images)
loss = compute_loss(outputs, labels)
print(f"Epoch {epoch}, Loss: {loss.item():.4f}, mAP50: {mAP50:.4f}")
5. 尝试使用官方提供的 YOLOv12 预训练权重
- 如果你使用的 YOLOv12 预训练权重不是官方提供的,可能会存在格式或结构上的不一致。
- 尽量从 YOLOv12 的官方仓库下载预训练权重。
三、可能的代码修改建议
如果你使用的是类似 ultralytics/yolov12 的项目,可以参考以下代码片段进行调整:
修改后的训练代码(假设你使用的是 PyTorch)
from yolov12.train import train
# 设置训练参数
cfg = {
"data": "data/coco.yaml",
"weights": "yolov12_pretrained.pt", # 确保路径正确
"epochs": 100,
"imgsz": 640,
"batch": 16,
"device": "0",
}
# 开始训练
train(cfg)
四、总结
| 问题 | 解决方案 |
|------|----------|
| 权重与模型结构不匹配 | 确认模型结构与预训练权重一致,使用 strict=False 跳过不匹配层 |
| 权重格式不兼容 | 确保使用正确的权重格式(如 .pt)并正确加载 |
| 配置不一致 | 检查 data.yaml、hyp.yaml 等配置文件是否与 YOLOv12 标准一致 |
| 训练不稳定 | 打印 loss 和 mAP,排查数据或标签问题 |
| 权重来源不明 | 使用官方提供的 YOLOv12 预训练权重 |
五、进一步建议
- 查阅 YOLOv12 官方文档,确认其权重格式、训练配置和模型结构。
- 尝试使用 YOLOv12 的官方训练脚本,对比你的代码是否有差异。
- 在 GitHub 或社区中搜索类似问题,看看是否有其他人遇到过类似情况。
如有需要,我可以帮助你 解析具体的权重文件内容 或 调试你的训练脚本。欢迎继续提问!