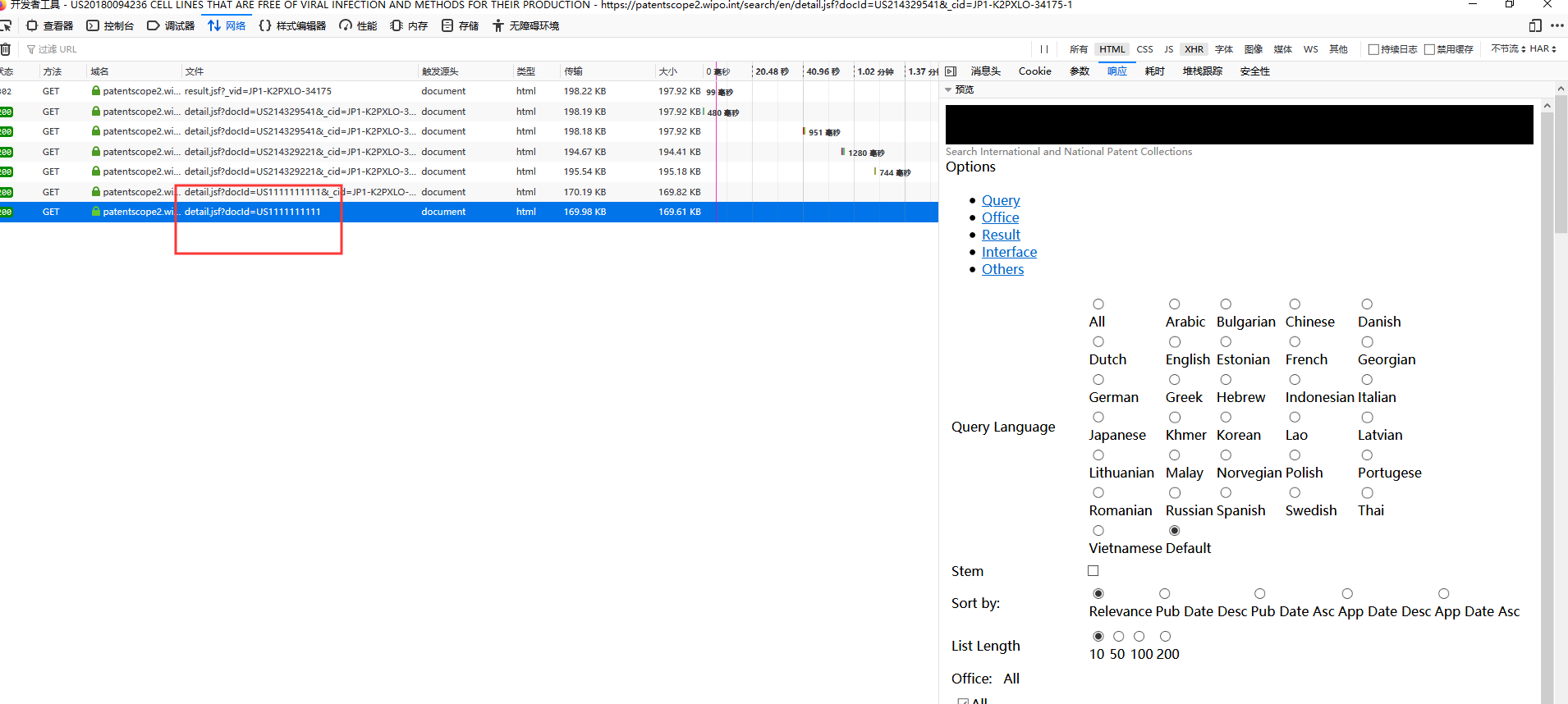
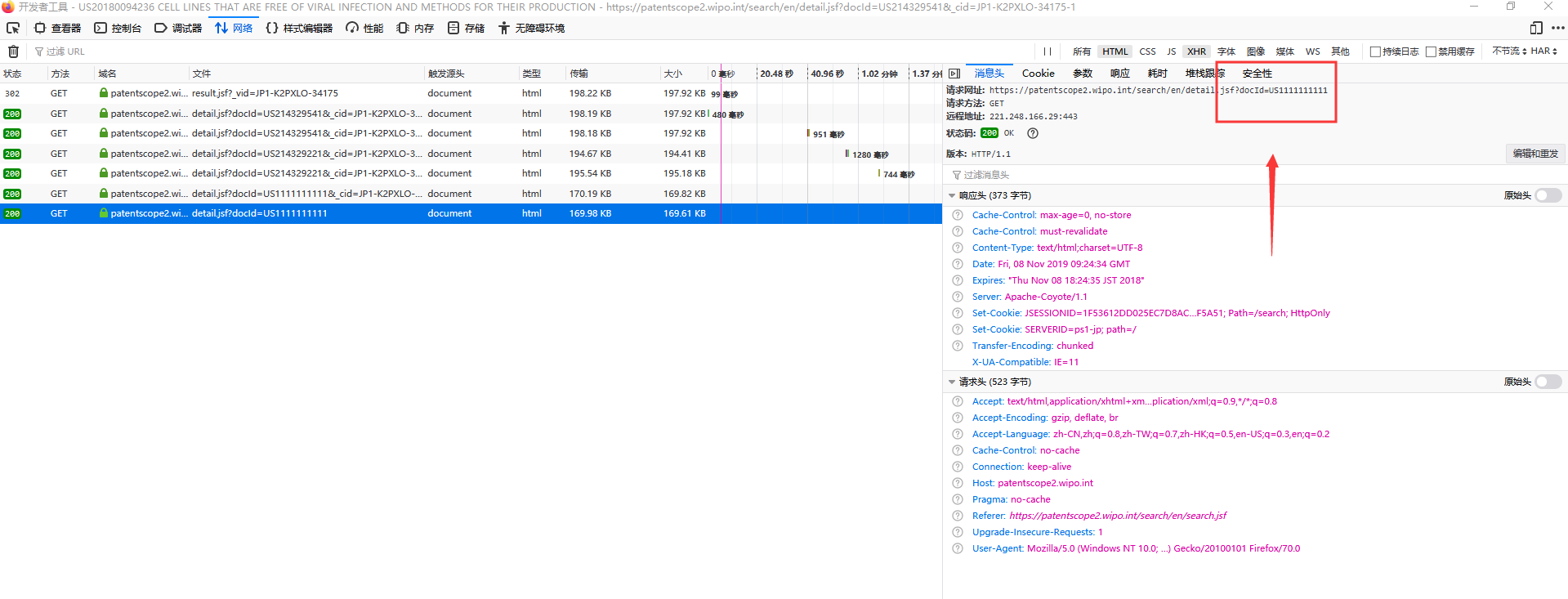
我想通过搜索值,获取下一级页面的网址,但是这个网址经过重定向处理,里面的docId是加工过的,不用selenium+浏览器的方法,我该如何获取这个docId值?
网址:https://patentscope2.wipo.int/search/en/search.jsf
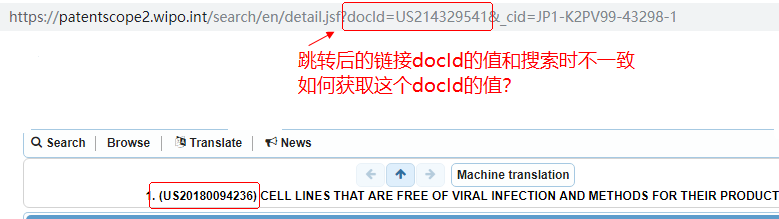
我输入的docId是 US20180094236
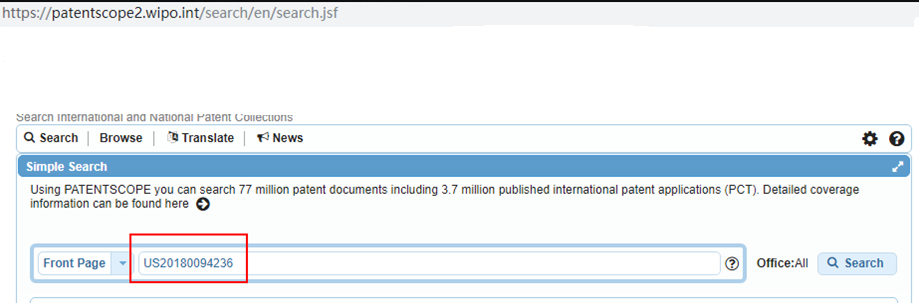
跳转页面后docId变成了 US214329541

我想通过搜索值,获取下一级页面的网址,但是这个网址经过重定向处理,里面的docId是加工过的,不用selenium+浏览器的方法,我该如何获取这个docId值?
网址:https://patentscope2.wipo.int/search/en/search.jsf
我输入的docId是 US20180094236
跳转页面后docId变成了 US214329541
 分享
分享






{kind=link}