import tensorflow as tf#导入Tensorflowimport numpy as np# 导入numpy
import matplotlib.pyplot as plt#导入matplotlib
print("Tensorflow版本是: ",tf.__version__) #显示当前TensorFlow版本
import numpy as np
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
total_num = len(train_images) # 划分验证集
valid_split = 0.2 # 验证集的比例为0.2
train_num = int(total_num*(1-valid_split)) # 训练集数目
train_x = train_images[:train_num] # 前部分给训练集
train_y = train_labels[:train_num]
valid_x = train_images[train_num:] # 后面20%部分给验证集合
valid_y = train_labels[train_num:]
test_x = test_images
test_y = test_labels
# 把(28 28)的结构拉直为一行784
train_x = train_x.reshape (-1,784)
valid_x = valid_x.reshape(-1,784)
test_x = test_x.reshape(-1,784)
# 归一化
train_x = tf.cast(train_x/255.0, tf.float32)
valid_x = tf.cast(valid_x/255.0, tf.float32)
test_x = tf.cast(test_x/255.0, tf.float32)
# 对标签数据进行独热编码
train_y = tf.one_hot(train_y,depth=10)
valid_y = tf.one_hot(valid_y,depth=10)
test_y = tf.one_hot(test_y, depth=10)
#定义第一层隐藏层权重和偏置项变量
Input_Dim = 784
H1_NN = 64
W1 = tf.Variable(tf.random.normal([Input_Dim, H1_NN], mean=0.0, stddev=1.0, dtype=tf.float32))
B1 = tf.Variable(tf.zeros([H1_NN]), dtype = tf.float32)
#定义输出层权重和偏置项变量
Output_Dim = 10
W2 = tf.Variable(tf.random.normal([H1_NN, Output_Dim], mean=0.0, stddev=1.0, dtype=tf.float32))
B2 = tf.Variable(tf.zeros([Output_Dim]), dtype = tf.float32)
#建立待优化变量列表
W = [W1, W2]
B = [B1, B2]
def model(x, w, b):
x = tf. matmul(x, w[0]) + b[0]
x = tf.nn.relu(x)
x = tf.matmul(x, w[1]) + b[1]
pred = tf.nn.softmax(x)
return pred
#定义交叉嫡损失函数
def loss(x, y, w, b):
pred = model(x, w, b)#计算模型预测值和标签值的差异
loss_ = tf.keras.losses.categorical_crossentropy(y_true=y, y_pred=pred)
return tf.reduce_mean(loss_)#求均值,得出均方差.
training_epochs = 20 # 训练轮数
batch_size = 50 # 单次训练样本数(批次大小)
learning_rate = 0.01 # 学习率
# 计算样本数据[x, y在参数[w, b]点上的梯度
def grad(x, y, w, b):
with tf.GradientTape() as tape:
loss_ = loss(x, y, w, b)
return tape.gradient(loss_, [w[0],b[0],w[1],b[1]])#返回梯度向量
# Adam优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
def accuracy (x,y, w, b):
pred = model(x, w, b) # 计算模型预测值和标签值的差异
# 检查预测类别tf.argmax (pred,1)与实际类别tf.argmax(y,1)的匹配情况
correct_prediction = tf.equal(tf.argmax(pred,1), tf.argmax(y, 1)) # 准确率,将布尔值转化为浮点数,并计算平均值
return tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
steps = int(train_num / batch_size) # 一轮训练有多少批次
loss_list_train = [] # 用于保存训练集loss值的列表
loss_list_valid = [] # 用于保存验证集loss值的列表
acc_list_train = [] # 用于保存训练集Acc值的列表
acc_list_valid = [] # 用于保存验证集Acc值的列表
for epoch in range(training_epochs):
for step in range(steps):
xs = train_x[step * batch_size:(step + 1) * batch_size]
ys = train_y[step * batch_size:(step + 1) * batch_size]
grads = grad(xs, ys, W, B) # 计算梯度
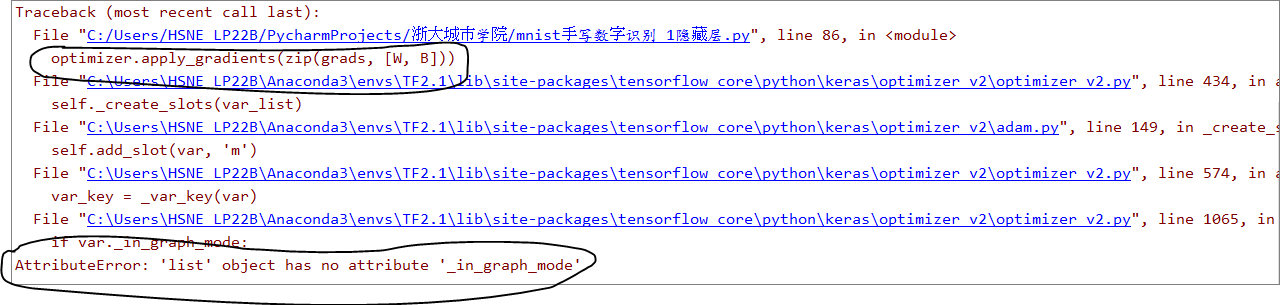
optimizer.apply_gradients(zip(grads, [W[0],B[0],W[1],B[1]])) # 优化器根据梯度自动调整变量w和b
loss_train = loss(train_x, train_y, W, B).numpy() # 计算当前轮训练损失
loss_valid = loss(valid_x, valid_y, W, B).numpy() # 计算当前轮验证损失
acc_train = accuracy(train_x, train_y,W,B).numpy()
acc_valid = accuracy(valid_x, valid_y, W, B).numpy()
loss_list_train.append(loss_train)
loss_list_valid.append(loss_valid)
acc_list_train.append(acc_train)
acc_list_valid.append(acc_valid)
print("epoch={:3d}, train_loss={:.4f}, train_acc={:.4f}, val_loss={:.4f}, val_acc={:.4f}".format(epoch + 1, loss_train, acc_train, loss_valid, acc_valid))
注意,这样是可以跑通的,问题应该是出现在拼接上。总共修改两处,计算loss,还有优化器那边算梯度