CNN分类模型,数据量大概40w左右,目前模型收敛性较好,无过拟合现象,有没有高人指点一下怎么优化模型。
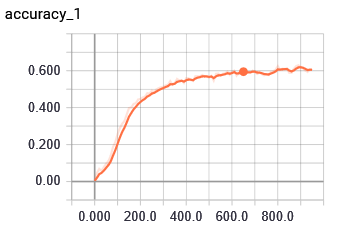
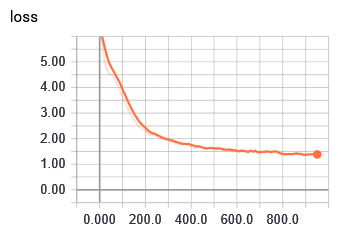
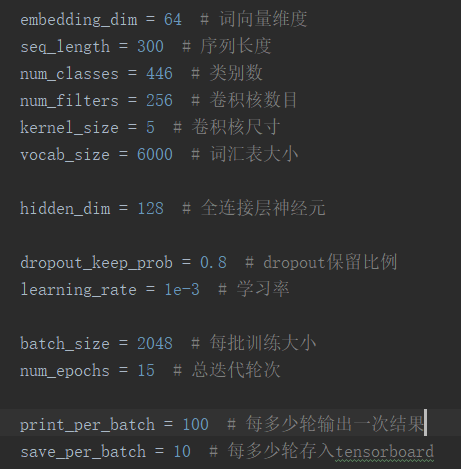

CNN分类模型,数据量大概40w左右,目前模型收敛性较好,无过拟合现象,有没有高人指点一下怎么优化模型。
 分享
分享
以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
要对 CNN 文本分类模型进行优化,您可以考虑以下几个方面:
调整超参数:在上述提供的图表中,可以看到 num_filters 和 embedding_dim 的变化对模型的性能产生了影响。您可以通过调整这两个参数来尝试不同的网络结构和特征提取方法。
对于 num_filters,可以尝试增加或减少它们的数量以找到最佳平衡点。
对于 embedding_dim,可以尝试使用更大的值(例如,将 embedding_dim = 64 更改为 embedding_dim = 128)以提高模型的表现。然而,较大的 embedding_dim 可能会增加过拟合的风险,因此应谨慎选择。
优化损失函数:根据经验,使用交叉熵损失函数(通常称为 crossentropy)可能是一个好选择,因为它能够很好地处理多类问题。但请注意,对于文本分类任务,有时使用特定的损失函数(如 binary_crossentropy 或 sparse_categorical_crossentropy),如 categorical_crossentropy,可能会提供更好的性能。
调整学习率:通过调整学习率,您可以控制模型的学习速度,从而避免过早地陷入局部最优解。一般来说,较小的学习率可能更稳定,而较大或较快的学习率可能导致过拟合。
正则化:正则化可以帮助防止过拟合,特别是当模型变得过于复杂时。一种常见的正则化技术是 L1 或 L2 正则化,它限制了模型中的权重和偏置的值,使其更加平滑。
验证集评估:为了确保模型的泛化能力,建议在训练过程中定期使用验证集来评估模型的表现,并在必要时调整模型参数。
以下是一个简单的示例代码,用于调整这些参数并可视化优化过程:
import numpy as np
from keras.models import Sequential
from keras.layers import Embedding, Conv1D, MaxPooling1D, Dense, Dropout
from keras.optimizers import Adam
# 定义模型架构
model = Sequential()
model.add(Embedding(vocabsize, embedding_dim, input_length=seqlength))
model.add(Conv1D(num_filters, kernel_size, activation='relu'))
model.add(MaxPooling1D(pool_size=pool_size))
model.add(Dropout(dropout_keep_prob))
# 添加全连接层
model.add(Dense(hiddendim, activation='relu'))
model.add(Dropout(dropout_keep_prob))
# 输出层
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(loss=categorical_crossentropy,
optimizer=Adam(lr=learning_rate),
metrics=['accuracy'])
# 训练模型
history = model.fit(x_train, y_train, epochs=num_epochs,
batch_size=batch_size,
validation_data=(x_val, y_val),
verbose=2)
# 显示训练和验证的准确性
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
# 显示训练和验证的损失
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
这段代码首先定义了一个简单的 CNN 模型,然后通过调用 fit() 函数对其进行训练。训练过程中,我们使用了交叉熵损失函数、Adam优化器以及适当的超参数设置。最后,我们绘制了训练和验证的准确性曲线以及损失曲线,以便观察模型的表现。
分享


