
b_model = pd.read_csv('C:/Users/USER/Desktop/b_model.csv')
b_model_skip = b_model.drop(['borrower_index','begin_time','withhold_time_first','num_period_percent',
'f01','f02','f03','f04','f05','f06','f07','f08','f09','f10'],axis=1)
b_model_dropnan = b_model_skip.dropna()
b_model_dropnan_independentvariable = b_model_dropnan.drop(['target'],axis=1)
b_model_dropnan_label = b_model_dropnan.target
x, y = b_model_dropnan_independentvariable, b_model_dropnan_label
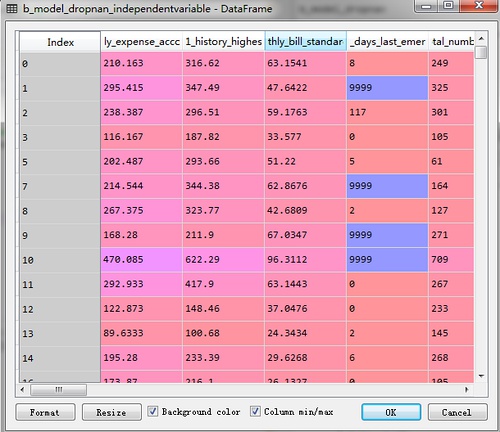
这时候,b_model_dropnan_independentvariable 是Dataframe数据框格式,具有列名。
from sklearn.feature_selection import VarianceThreshold
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
b_model_dropnan_variancethreshold = sel.fit_transform(b_model_dropnan_independentvariable)
当我使用sklearn移除低方差特征后,b_model_dropnan_variancethreshold 是arrat数组格式,是没有列名的。
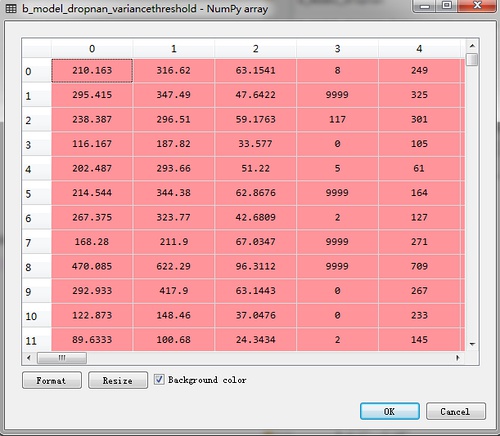
这种情况下,首先,我确认是可以通过算法建立模型的,但数组没有列名的情况下,我后面如何确认feature importance呢?只确认留下是哪些与target高度相关的变量。
也无法转换为dataframe格式,然后重命名,毕竟特征数量过多,无法一一比对重新命令,而且有的低相关性变量也会变删除,很难进行比对。






