
- 我使用的是官网的代码https://github.com/tensorflow/models/tree/master/research/deeplab 复现deeplab v3+;
- 训练数据就是标准的Pascal voc2012。训练之前已经按照官网上的说法,通过运行脚本download_and_convert_voc2012.sh下载voc2012数据、并将label转换为单通道、并将数据转换为需要的tfrecord格式;
- 训练模型也是从提供的model_zoo下载的https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/model_zoo.md;
- 学习率保持默认,即learning rate=0.0001;
- Linux Ubuntu 16.04;TensorFlow1.6.0 installed from Anaconda;CUDA9.0/cudnn7.0.5;GeForce GTX 1080 Ti;
- 具体训练代码是:
python deeplab/train.py \
--logtostderr \
--training_number_of_steps=30000 \
--train_split="train" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--train_crop_size=513 \
--train_crop_size=513 \
--train_batch_size=2 \
--dataset="pascal_voc_seg" \
--fine_tune_batch_norm = False \
--tf_initial_checkpoint="{下载的checkpoint路径}/deeplabv3_pascal_train_aug/model.ckpt.index" \
--train_logdir="{要写入路径}/exp/train_on_train_set/train" \
--dataset_dir="{数据集路径}/pascal_voc_seg/tfrecord"
- 然而loss一直不收敛:
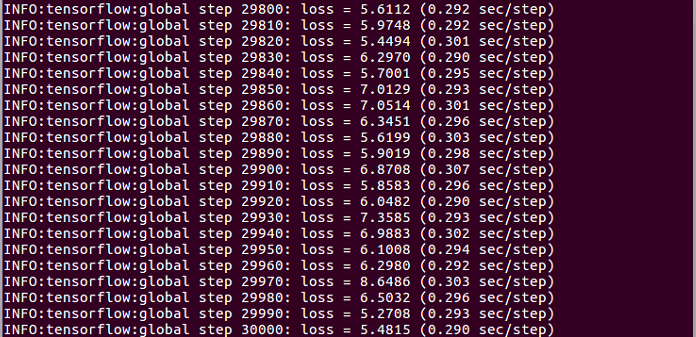
- 最终出现nan值错误

如果训练的次数少一点,验证一下结果,发现miou只有零点零几:
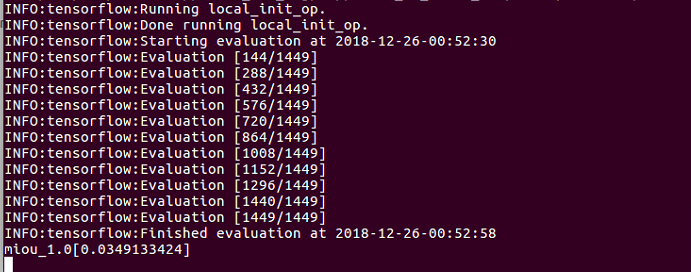
一直没有找到原因,感觉步骤没有问题,也参照过各种博客,大家似乎都没有出现这种情况,希望大佬们可以帮忙



