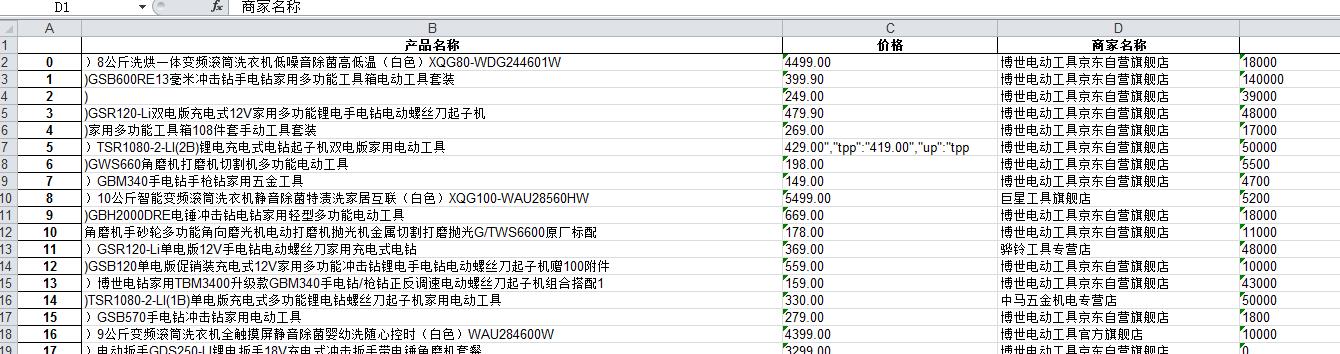
导出的结果是一张只有表头没有数据的空表。
#信息采集:名称、价格、评论数、商家名称等
import requests
from lxml import etree
from pandas import DataFrame
import pandas as pd
jdInfoAll=DataFrame()
for i in range(1,4):
url="https://search.jd.com/Search?keyword=bosch&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&bs=1&suggest=1.his.0.0&ev=exbrand_%E5%8D%9A%E4%B8%96%EF%BC%88BOSCH%EF%BC%89%5E&page="+str(i)
res=requests.get(url)
res.encoding='utf-8'
root=etree.HTML(res.text)
name=root.xpath('//*[@id="J_goodsList"]/ul/li[@class="gl-item"]/div/div[@class="p-name p-name-type-2"]/a/em/text()[2]')
for i in range(0,len(name)):
name[i]=re.sub('\s','',name[i])
print(i)
#sku
sku=root.xpath('//*[@id="J_goodsList"]/ul/li/@data-sku')
print(sku)
#价格
price=[]
comment=[]
for i in range(0,len(sku)):
thissku=sku[i]
priceurl="https://p.3.cn/prices/mgets?callback=jQuery6775278&skuids=J_"+str(thissku)
pricedata=requests.get(priceurl)
pricepat='"p":"(.*?)"}'
thisprice=re.compile(pricepat).findall(pricedata.text)
price=price+thisprice
commenturl="https://club.jd.com/comment/productCommentSummaries.action?my=pinglun&referenceIds="+str(thissku)
commentdata=requests.get(commenturl)
commentpat='"CommentCount":(.*?),"'
thiscomment=re.compile(commentpat).findall(commentdata.text)
comment=comment+thiscomment
#商家名称
shopname=root.xpath('//*[@id="J_goodsList"]/ul/li[@class="gl-item"]/div/div[@class="p-shop"]/span/a/@title')
print(shopname)
jdInfo=DataFrame([name,price,shopname,comment]).T
jdInfo.columns=['产品名称','价格','商家名称','评论数']
jdInfoAll=pd.concat([jdInfoAll,jdInfo])
jdInfoAll.to_excel('jdInfoAll.xls')