我最近使用自己的数据集(只有1类)训练好了yolox_nano.pth模型,想把这个yolox_nano.pth转换成yolox_nano.onnx,但是报了很多错误:
转换命令(在YOLOX目录下):
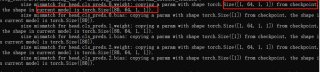
python tools/export_onnx.py -n yolox-nano -c weights/yolox_nano.pth --output-name weights/yolox_nano.onnx
报错信息:
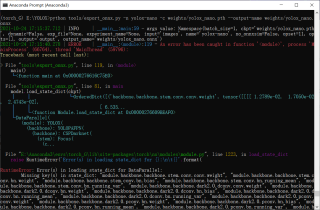
RuntimeError: Error(s) in loading state_dict for DataParallel:
Missing key(s) in state_dict: ....
Unexpected key(s) in state_dict...
报错图如下:
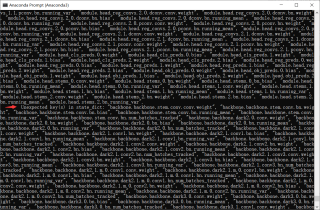
我认为报错的原因是因为我转换的是自己的数据集,而我转换coco数据集的时候却不会报错,可以正常转换:
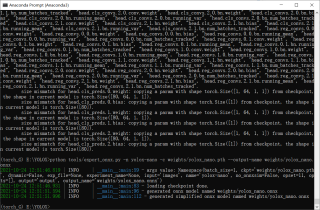
但我已经修改了yolox_base.py里面的num_classes、depth、width还有input_size这些:
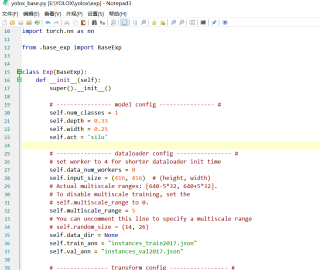
还是报这个错误
完整报错信息如下:
(torch_G) E:\YOLOX>python tools/export_onnx.py -n yolox-nano -c weights/yolox_nano.pth --output-name weights/yolox_nano.onnx
2021-10-24 17:15:37.712 | INFO | __main__:main:59 - args value: Namespace(batch_size=1, ckpt='weights/yolox_nano.pth', dynamic=False, exp_file=None, experiment_name=None, input='images', name='yolox-nano', no_onnxsim=False, opset=11, opts=[], output='output', output_name='weights/yolox_nano.onnx')
2021-10-24 17:15:40.278 | ERROR | __main__:<module>:119 - An error has been caught in function '<module>', process 'MainProcess' (66764), thread 'MainThread' (59796):
Traceback (most recent call last):
> File "tools\export_onnx.py", line 119, in <module>
main()
└ <function main at 0x00000276616C75E0>
File "tools\export_onnx.py", line 81, in main
model.load_state_dict(ckpt)
│ │ └ OrderedDict([('backbone.backbone.stem.conv.conv.weight', tensor([[[[ 1.2789e-02, 1.7050e-02, 2.4743e-02],
│ │ [ 6.535...
│ └ <function Module.load_state_dict at 0x00000276609BEAF0>
└ DataParallel(
(module): YOLOX(
(backbone): YOLOPAFPN(
(backbone): CSPDarknet(
(stem): Focus(
(c...
File "E:\Anaconda3\envs\torch_G\lib\site-packages\torch\nn\modules\module.py", line 1223, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for DataParallel:
Missing key(s) in state_dict: "module.backbone.backbone.stem.conv.conv.weight", "module.backbone.backbone.stem.conv.bn.weight", "module.backbone.backbone.stem.conv.bn.bias"......
Unexpected key(s) in state_dict: "backbone.backbone.stem.conv.conv.weight", "backbone.backbone.stem.conv.bn.weight", "backbone.backbone.stem.conv.bn.bias"....
我认为是网络的问题,多了或者少了什么参数,导致不匹配。
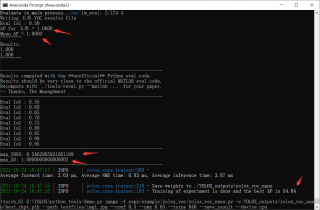
我训练好的的yolox_nano.pth是没问题的,可以正常预测(推理):

那就感觉很奇怪了,希望有可以有这方面经验的同学可以帮我回答一下,谢谢。