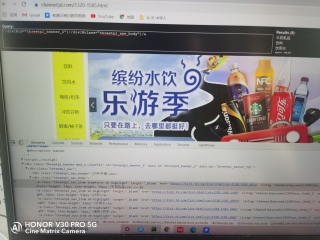
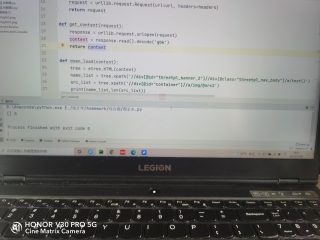
在XPath的小黑框中已经能找到我要找的东西,但是运行代码时 输出为零
收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
爬虫代码发出来啊,要不别人咋帮你分析
报告相同问题?

 分享
分享 系统已结题
11月29日
系统已结题
11月29日 已采纳回答
11月21日
修改了问题
11月20日
修改了问题
11月20日
已采纳回答
11月21日
修改了问题
11月20日
修改了问题
11月20日





